Next Gen Data Processing at Massive Scale At Pinterest With Moka (Part 2 of 2)
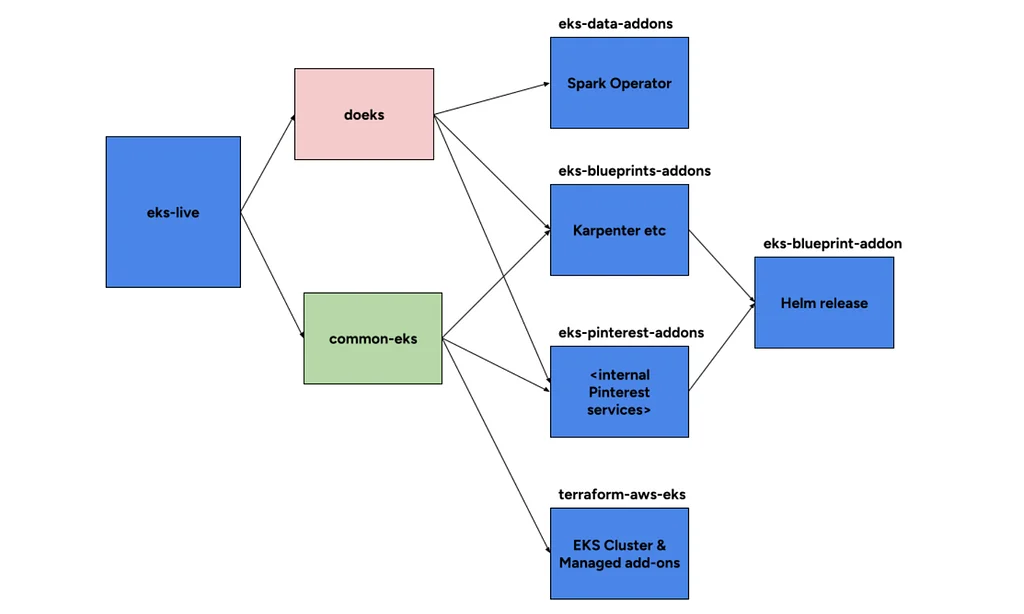
Pinterest is developing Moka, a next-generation data processing platform, to replace its aging Hadoop-based system. This platform is deployed on AWS Elastic Kubernetes Service (EKS) across four environments: test, dev, staging, and production. Terraform, augmented by custom AWS modules and Helm charts, manages the EKS cluster deployments. A critical component of Moka is its logging infrastructure, which utilizes Fluent Bit to collect and export logs from EKS control planes, Spark applications, and system pods to Amazon S3. Fluent Bit is configured to group Spark application logs by a unique job ID and to parse YuniKorn logs for resource usage summaries. For observability, Pinterest employs a Prometheus-compatible framework to gather metrics. They developed a custom sidecar, kubemetricsexporter, to bridge their existing TSDB-based Statsboard system with Prometheus metrics. The OpenTelemetry Collector is used to receive, process, and export telemetry data, with a specific pipeline configured for Prometheus metrics. This robust infrastructure aims to ensure efficient and reliable data processing at massive scale for Pinterest.