Optimizing ML Workload Network Efficiency (Part I): Feature Trimmer
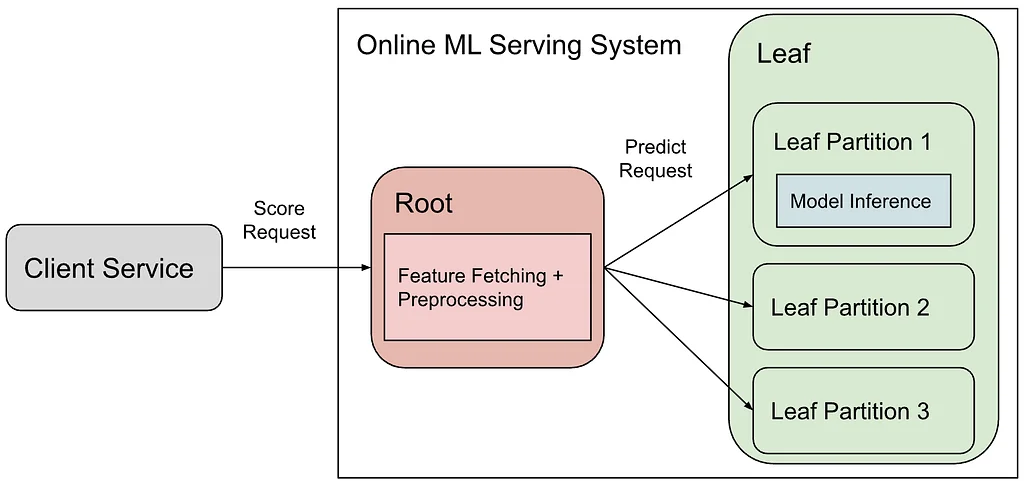
Pinterest's online ML serving system uses a root-leaf architecture where client services request scores for Pins. The root component handles feature retrieval and preprocessing, while leaves perform model inference, often on GPUs. This design simplifies onboarding new models and optimizes resource utilization by separating CPU and GPU workloads. However, it led to a network bottleneck between the root and leaf partitions due to passing many features.Initially, lz4 compression was implemented to reduce network usage, resulting in significant bandwidth savings but with a slight increase in CPU usage and latency. This was a good start, but the core issue of shipping unnecessary features persisted. The "Send What You Use" approach was then developed to address this by only sending features that a specific model requires.The model signature, which defines a model's inputs and outputs, serves as the source of truth for feature requirements. As models are trained and exported, their signatures are saved alongside them. Leaften load these signatures to build feature converters that process only the necessary features.To synchronize feature requirements between the root and leaves, model signatures are published as lightweight artifacts. These signatures are aggregated into bundle-level mappings, which are then deployed to the root alongside existing configurations. This deployment follows the same staged delivery process as model rollouts, ensuring consistency and enabling graceful rollbacks.This integration allows the Feature Trimmer to dynamically update feature allowlists on the root, ensuring that only essential features are transmitted. The system is designed to handle frequent model updates and gradual rollouts by using versioned lookups and fallback mechanisms. This ensures that the root's view of required features stays synchronized with the actual models deployed on the leaves. By trimming unneeded features, Pinterest significantly reduced network traffic and improved infrastructure efficiency.