Pinterest's ML training platform, MLEnv, encountered a significant performance drop after a PyTorch version upgrade. This issue led to a more than 50% reduction in training throughput. The debugging process began by examining the GPU roofline throughput. This measurement revealed a 20% performance decrease even when excluding the data loader. Further analysis focused on individual model modules to pinpoint the source of the slowdown. A specific transformer module, module A, was identified as the primary culprit. The PyTorch profiler showed that CompiledFunctions, previously present, were now missing for this module in the upgraded version.Investigation into torch.compile revealed a log indicating that a non-infrastructure PyTorch dispatch mode was present, which torch.compile did not support. Minimal reproducible scripts confirmed that this issue manifested specifically within the trainer class. The problematic component was identified as a context manager used for FLOPs counting, enabled by default. Disabling this context manager resolved the torch.compile issue, restoring CompiledFunctions. However, this fix did not improve end-to-end throughput.The focus shifted back to the data loading and distributed training aspects, ruling out Ray.data as the cause by observing the same GPU roofline throughput issues even when running as a native PyTorch application. Several observations pointed to intermittent slow iterations, a straggler effect during synchronization, and a peculiar behavior where enabling Nvidia's Nsight Systems profiler eliminated the slowness. Testing on a single GPU confirmed distributed training was not the root cause. Disabling torch.compile entirely in the Ray setup restored original throughput, suggesting that graph breaks within torch.compile were related to the slowdowns.Creating a minimal reproducible model with extensive graph breaks led to the observation of recurring slow iterations. Nsight Systems traces revealed that the main training thread was holding the Global Interpreter Lock (GIL) during these slow iterations, but this did not explain the entire pause. Further analysis using the Linux perf tool and visualizing the traces with chrome://tracing highlighted a suspicious Python process. This process was executing an expensive computation, specifically a Linux kernel call named smap_gather_stats, which gathers virtual memory statistics.
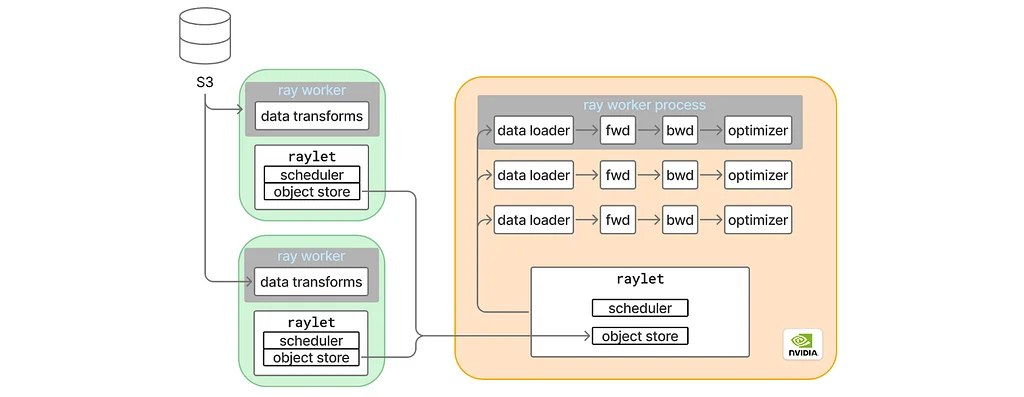
torch.compilerevealed a log indicating that a non-infrastructure PyTorch dispatch mode was present, whichtorch.compiledid not support. Minimal reproducible scripts confirmed that this issue manifested specifically within the trainer class. The problematic component was identified as a context manager used for FLOPs counting, enabled by default. Disabling this context manager resolved thetorch.compileissue, restoring CompiledFunctions. However, this fix did not improve end-to-end throughput.The focus shifted back to the data loading and distributed training aspects, ruling out Ray.data as the cause by observing the same GPU roofline throughput issues even when running as a native PyTorch application. Several observations pointed to intermittent slow iterations, a straggler effect during synchronization, and a peculiar behavior where enabling Nvidia's Nsight Systems profiler eliminated the slowness. Testing on a single GPU confirmed distributed training was not the root cause. Disablingtorch.compileentirely in the Ray setup restored original throughput, suggesting that graph breaks withintorch.compilewere related to the slowdowns.Creating a minimal reproducible model with extensive graph breaks led to the observation of recurring slow iterations. Nsight Systems traces revealed that the main training thread was holding the Global Interpreter Lock (GIL) during these slow iterations, but this did not explain the entire pause. Further analysis using the Linuxperftool and visualizing the traces withchrome://tracinghighlighted a suspicious Python process. This process was executing an expensive computation, specifically a Linux kernel call namedsmap_gather_stats, which gathers virtual memory statistics.