Next Gen Data Processing at Massive Scale At Pinterest With Moka (Part 1 of 2)
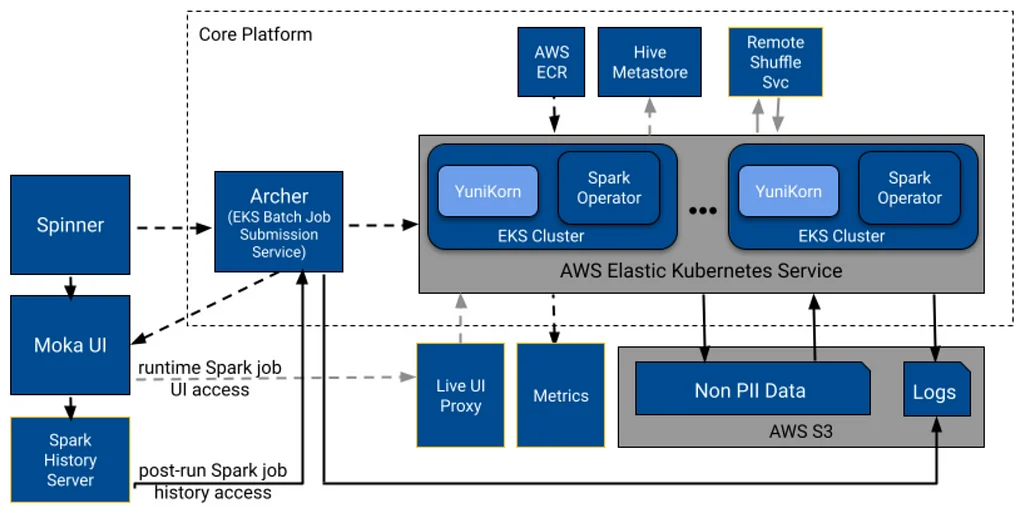
Pinterest's Data Engineering team is building a new massive scale data processing platform to replace their current Hadoop-based platform, Monarch. The team explored Kubernetes-based systems as a replacement due to their growing popularity and increasing adoption in the Big Data community. The new platform had to meet certain criteria, including extensive support for containers, execution of Pinterest's custom Spark fork, and lower operational and maintenance costs. The team performed a comprehensive evaluation of running Spark on various platforms and leaned towards Kubernetes-focused frameworks due to their advantages, including container-based isolation and security, ease of deployment, and built-in frameworks. Kubernetes provides more fine-grained support for container management and deployment than other systems, but lacks built-in support for data management, storage, and processing. The team's current deployment model in Hadoop is cumbersome, and they are moving towards a more straightforward approach using Terraform, container images, and Helm. The new platform will leverage Kubernetes and EKS to replace Monarch, introducing several challenges, including integrating EKS into the existing Pinterest environment and finding replacements for Hadoop components. The team has built a new platform, Moka, which is able to process batch Spark workloads that only access non-sensitive data, and will add more functionality in the future. The initial high-level design of Moka includes a system that can process batch Spark workloads, with jobs submitted and processed through a series of components, including Spinner, Archer, and the Spark Operator. The team will provide more details on the core application-focused aspects of their platform in the next part of their blog series.