Multi-gate-Mixture-of-Experts (MMoE) model architecture and knowledge distillation in Ads…
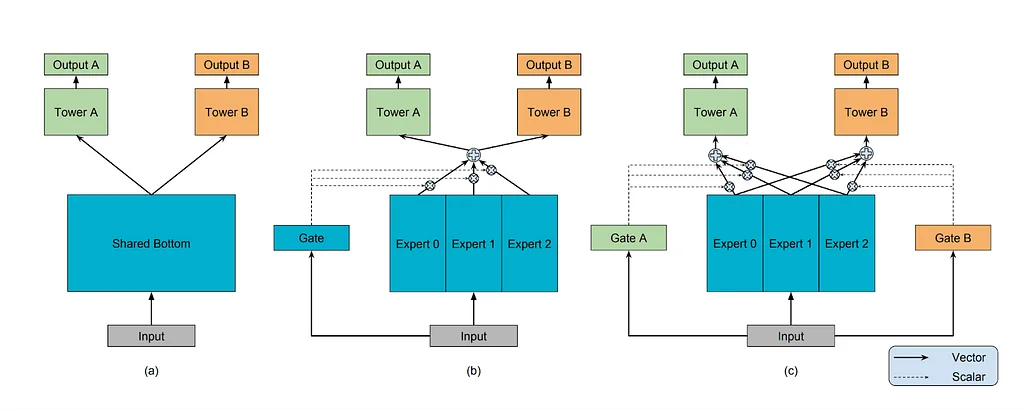
The Multi-gate Mixture-of-Experts (MMoE) model architecture improves ad engagement modeling by dynamically allocating resources to specialized sub-networks (experts). This improves efficiency, generalization, and multi-task learning compared to single models. MMoE leverages experts with diverse architectures like DCNv2, MaskNet, and FinalMLP, strategically chosen based on performance and cost. The model also utilizes mixed precision inference and lightweight gate layers to reduce infrastructure costs without sacrificing performance. Knowledge distillation further enhances the model by transferring knowledge from existing production models to new models. This mitigates performance gaps caused by limited data retention periods and allows new models to learn from unavailable historical data. Distillation improves both offline and online metrics significantly, surpassing the baseline DCNv2 model. The technique is beneficial during both batch training and model retraining scenarios, such as feature upgrades. However, distillation is removed during incremental training to prevent overfitting. The combined approach of MMoE and knowledge distillation leads to substantial improvements in ad matching quality and user experience. This results in more relevant recommendations and improved user engagement on the platform.