Scaling Recommendation Systems with Request-Level Deduplication
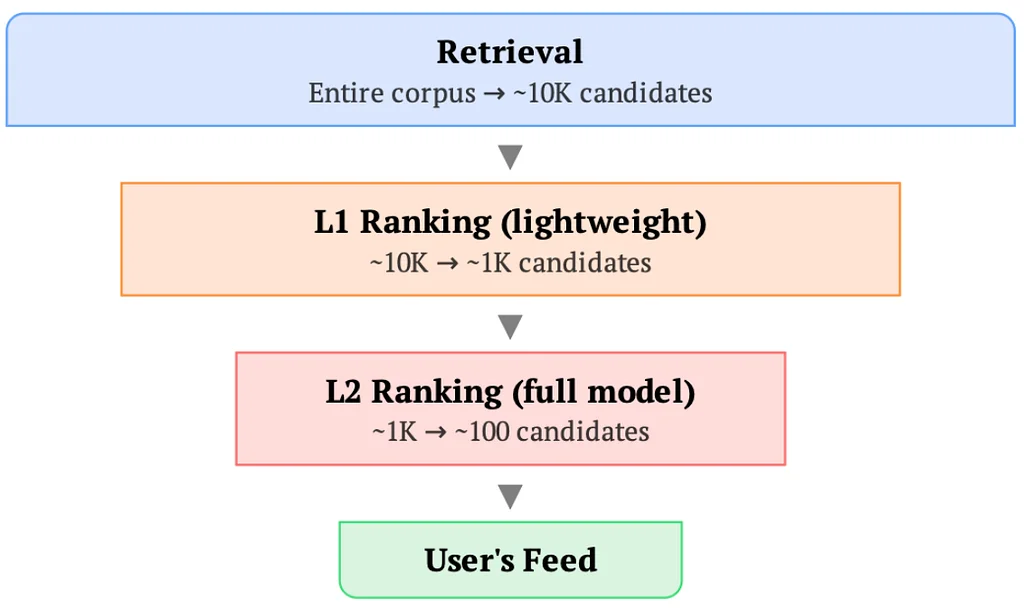
Pinterest leverages request-level deduplication to optimize its recommendation models and manage infrastructure costs. This technique avoids redundant processing of request-level data, which includes massive user action sequences. Deduplication significantly reduces storage needs, with storage compression reaching 10-50x on user-heavy feature columns using Apache Iceberg. While implementing request-sorted data, they addressed issues and maintained model quality through SyncBatchNorm and user-level masking. This led to significant training speedups, with a 4x improvement for retrieval models and 2.8x for ranking models. This also improved serving throughput, enabling a 7x increase in ranking serving capacity using the Deduplicated Cross-Attention Transformer (DCAT) architecture. This comprehensive approach, yielded impactful improvements across storage, training, and serving. Ultimately, request-level deduplication is a cross-cutting technique with simple but effective solutions.