Scaling Pinterest ML Infrastructure with Ray: From Training to End-to-End ML Pipelines
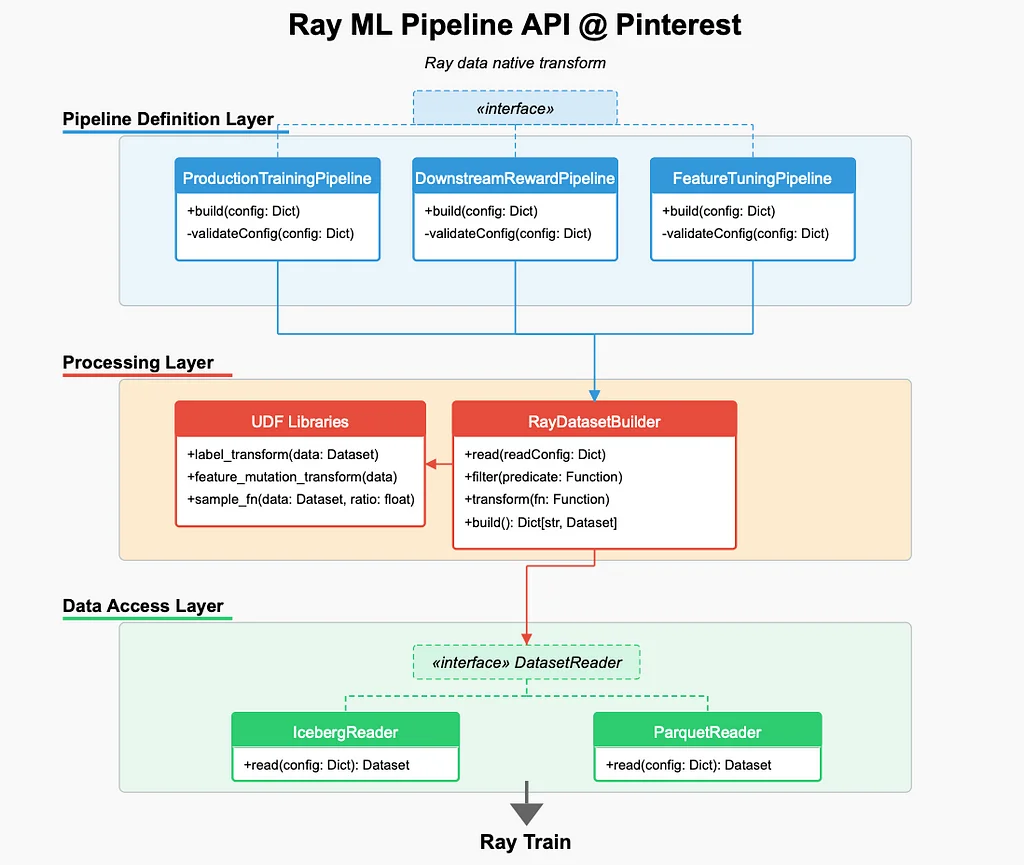
At Pinterest, ML engineers face challenges in optimizing feature development, sampling strategies, and label experimentation due to slow data pipelines, costly feature iterations, and inefficient compute usage. To address these challenges, Pinterest expanded Ray's capabilities beyond training to feature development, sampling, and label modeling. The traditional ML infrastructure was constrained by slow data pipelines, costly feature iterations, and inefficient compute usage. Pinterest introduced a Ray-native ML infrastructure stack, focusing on four major improvements: building a Ray Data native pipeline API, efficient data joining with Iceberg Bucket Joins, data persistence for efficient iteration, and Ray Data optimizations for large workloads. The new Ray-powered ML workflow reduces ML iteration times by 10X while significantly cutting infrastructure costs. The Ray Data native pipeline API enables feature development, sampling, and label transformations natively in Ray, eliminating the need for Spark backfills. Iceberg Bucket Joins enable fast and efficient feature joins across different sources without precomputing large tables. Data persistence allows for efficient iteration by caching transformed features and reusing them when applicable. The Ray Data optimizations achieved a 2-3X speedup across different pipelines, and the new workflow has unlocked a more scalable, efficient, and cost-effective ML infrastructure at Pinterest.