Blog de IA de Google RSS
Seguir
Asegurando datos privados a escala con selección de particiones diferencialmente privada
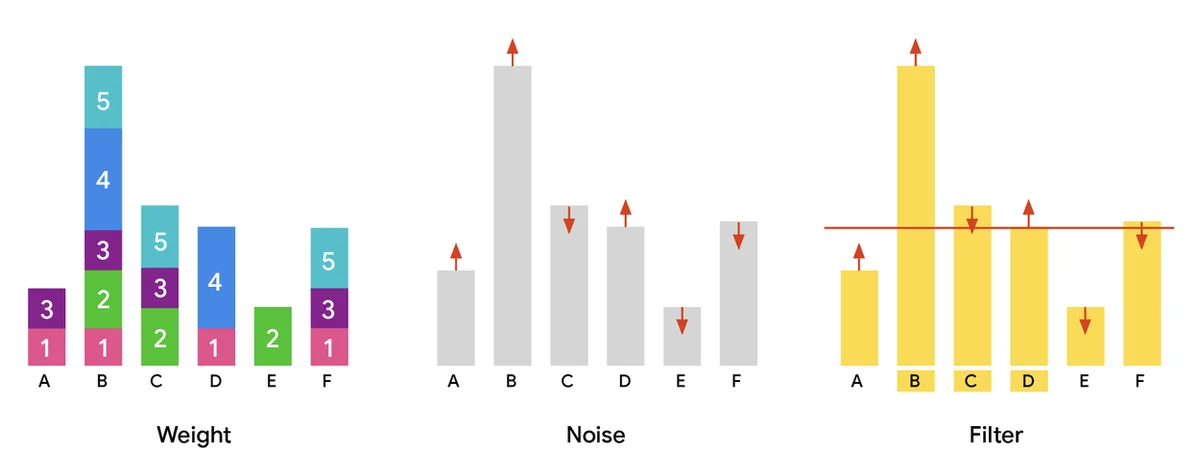
"Los conjuntos de datos de gran tamaño basados en usuarios son vitales para el avance de la IA, mejorando los servicios y la personalización. Compartir estos conjuntos de datos acelera la investigación pero plantea riesgos para la privacidad. La selección de particiones con privacidad diferencial (DP) identifica subconjuntos de datos seguros y comunes añadiendo ruido para proteger las contribuciones individuales. Esto es crucial para tareas como la extracción de vocabulario y el análisis de datos privados. Procesar conjuntos de datos masivos requiere algoritmos paralelos, no solo por velocidad sino para manejar escalas inmensas. Nuestra publicación, "Scalable Private Partition Selection via Adaptive Weighting" (Selección de Particiones Privadas Escalables mediante Ponderación Adaptativa), introduce un algoritmo paralelo eficiente para la selección de particiones DP. Este algoritmo escala a cientos de miles de millones de elementos, superando significativamente las capacidades previas. El objetivo es maximizar los elementos seleccionados mientras se preserva la privacidad del usuario, priorizando los datos populares. El enfoque estándar implica la ponderación, la adición de ruido y el filtrado de elementos basándose en un umbral. Nuestro novedoso algoritmo de ponderación adaptativa, MAD, reasigna el "peso excesivo" de los elementos populares a aquellos que están justo por debajo del umbral de privacidad. Esto mejora la utilidad al incluir más elementos sin comprometer la privacidad ni la escalabilidad. Los experimentos demuestran que nuestro algoritmo MAD de dos iteraciones logra resultados de vanguardia, produciendo más elementos que otros métodos con las mismas garantías de privacidad. Estamos liberando nuestro algoritmo de código abierto para fomentar la innovación comunitaria."