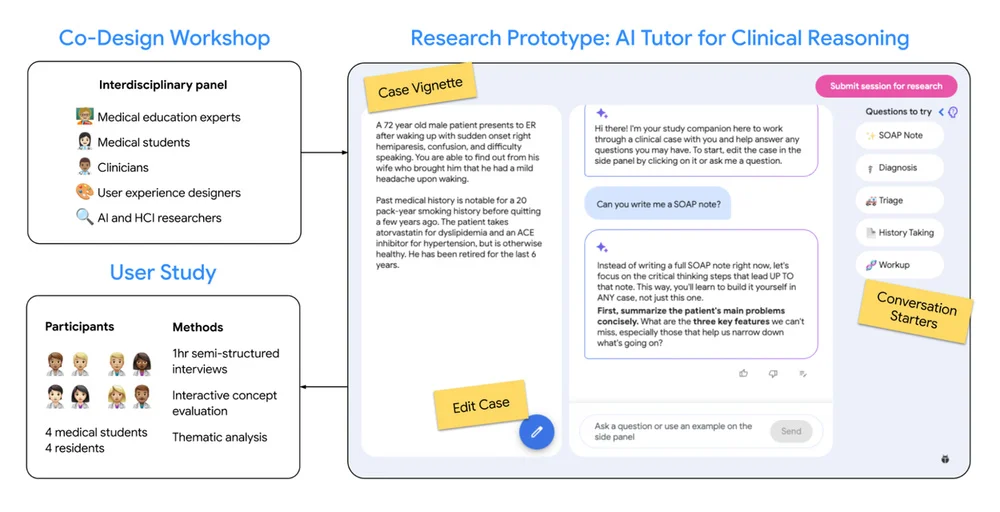
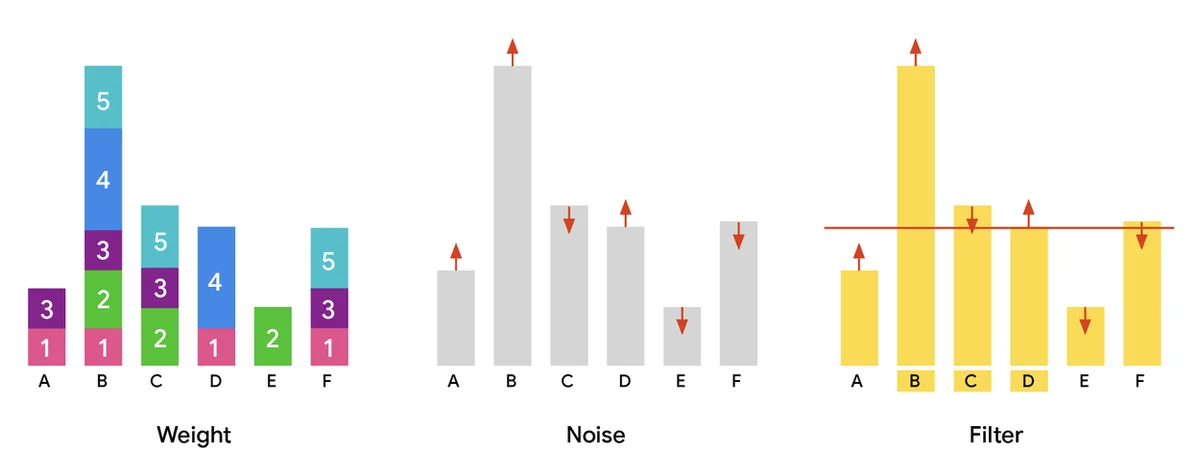
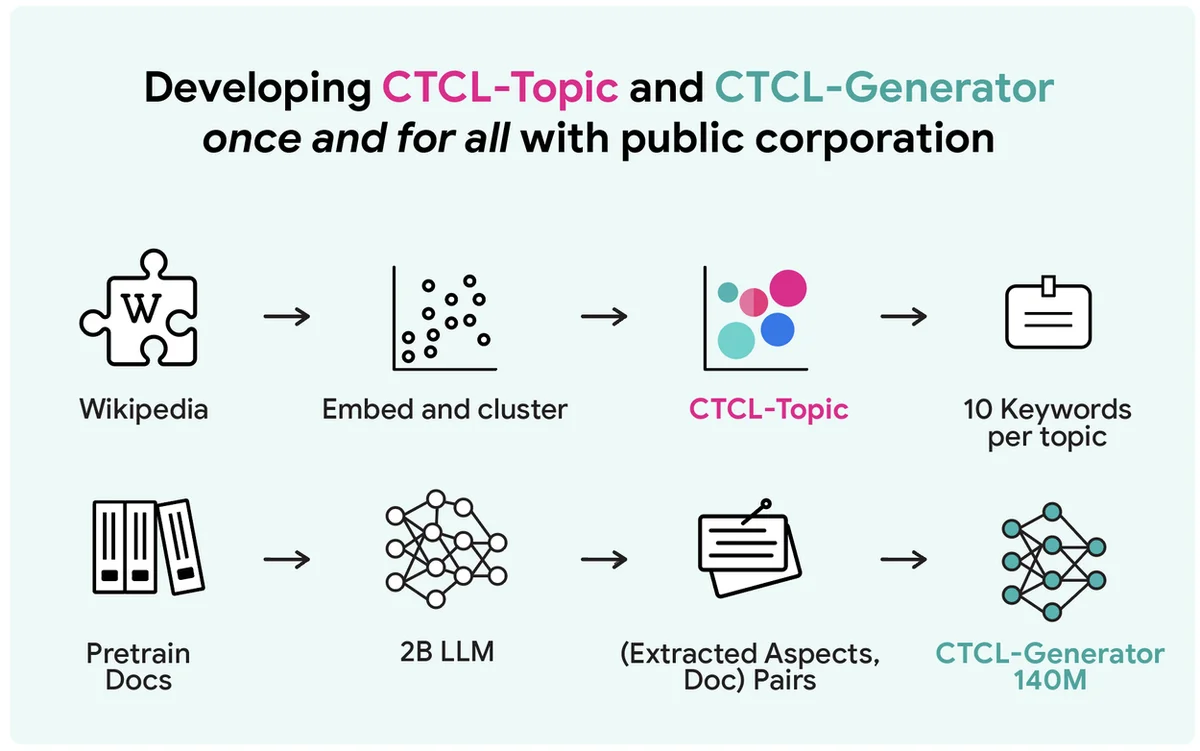
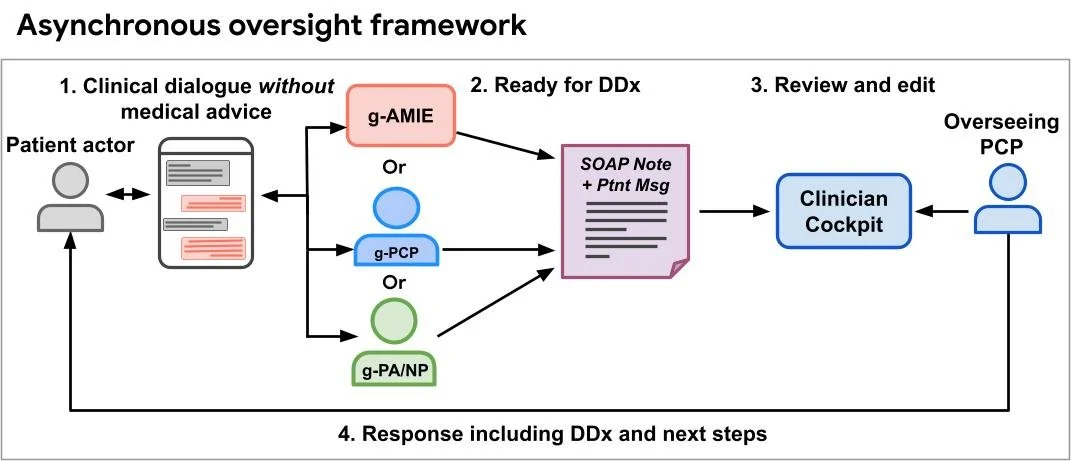
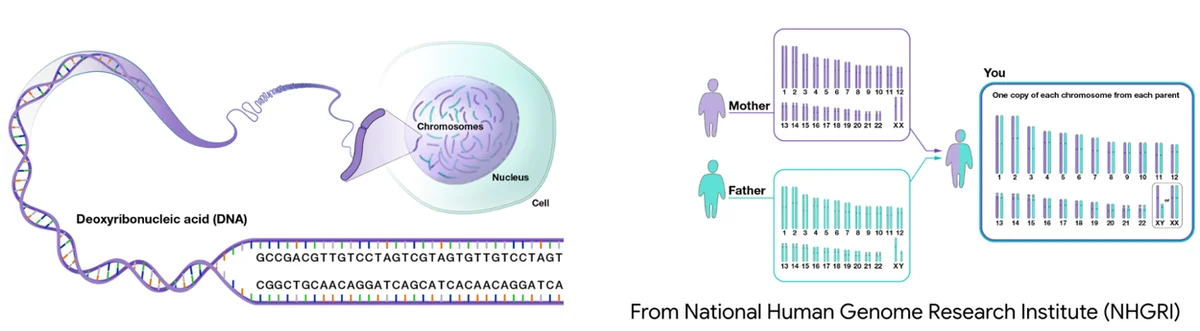
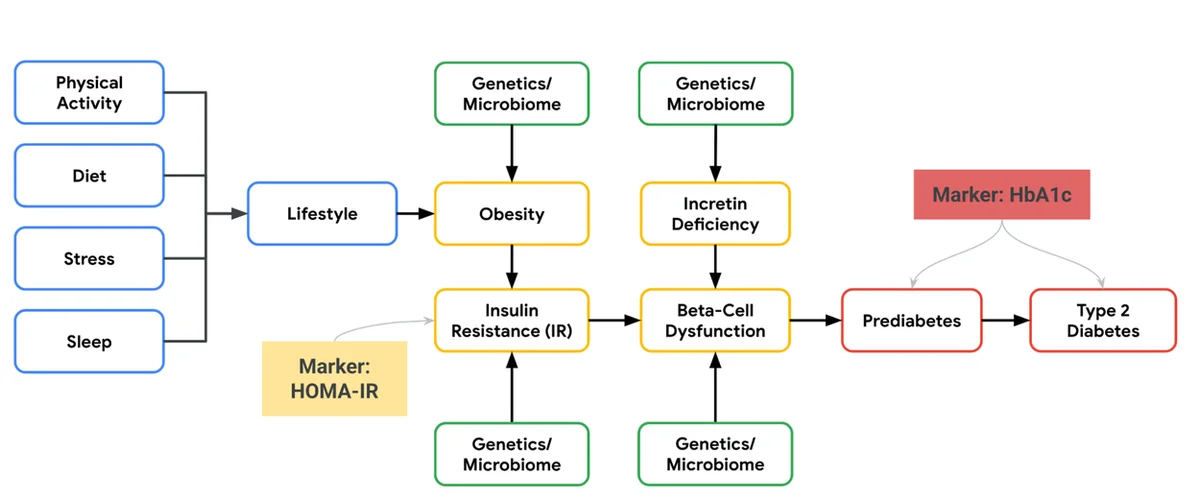
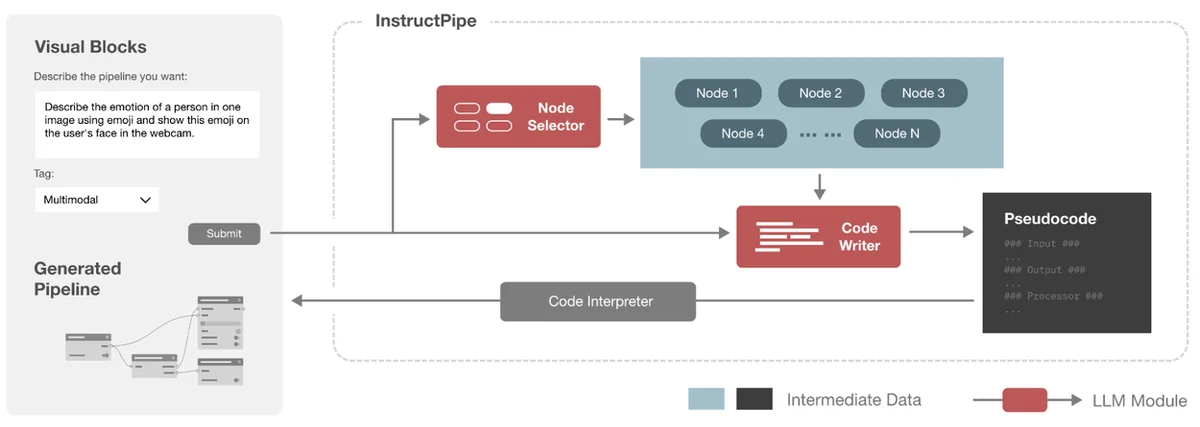
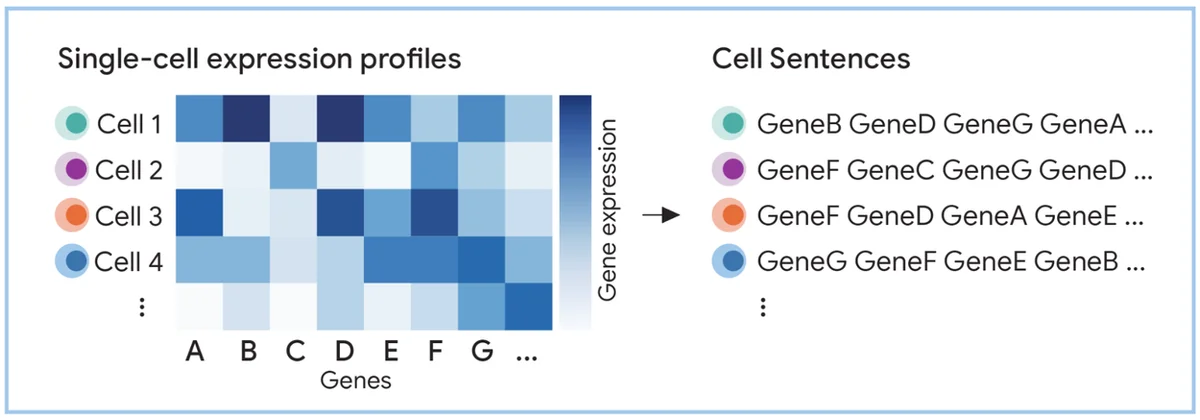
Blog de IA de Google RSS Seguir
El blog de Google Research es un medio destinado a compartir los últimos avances y perspectivas de la comunidad científica de Google Research. Esta plataforma sirve como un medio para que los investigadores se comuniquen con usuarios fuera de los círculos científicos, discutiendo nuevas y prometedoras tecnologías, ideas y innovaciones.Google Research publica con frecuencia sobre diversos temas científicos, que van desde la inteligencia artificial y el aprendizaje automático hasta innovaciones en la atención médica. También se adentra en nuevas tecnologías, desde automóviles autónomos hasta técnicas de diagnóstico médico y análisis de datos de vanguardia.Una característica notable del blog es la contribución de los miembros del equipo. Muchos de los principales tecnólogos y investigadores de Google aportan artículos reveladores que reflejan sus variadas habilidades y intereses. Este sitio ofrece la oportunidad de leer relatos de primera mano sobre los últimos avances y visiones futuras del mundo tecnológico.El blog cuenta con una sección de "autores", lo que permite a los usuarios acceder a artículos y ideas de los colaboradores individuales. Además de discusiones técnicas y innovaciones, el blog también se ocupa de cuestiones sociales y filosóficas más amplias relacionadas con nuevas tecnologías, brindando a los usuarios una comprensión más completa de cómo la tecnología afecta nuestra vida cotidiana.En esencia, el blog de Google Research ofrece una mezcla única de experiencia técnica, avances en la investigación y implicaciones sociales, lo que lo hace un recurso valioso para entusiastas de la tecnología, investigadores y cualquier persona interesada en comprender y dar forma a las tecnologías futuras.