Blog de IA de Google RSS
Seguir
Más allá de las cargas de parámetros de billones: Desbloquear la síntesis de datos con un generador condicional
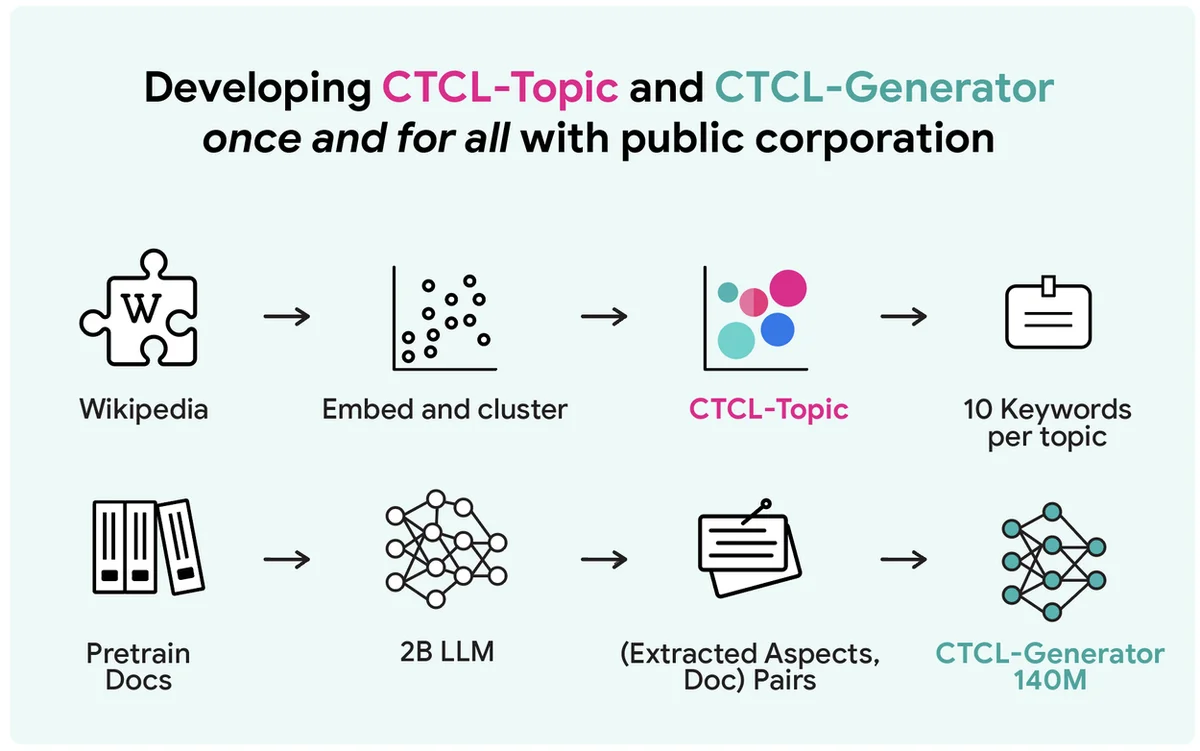
La generación de datos sintéticos de texto a gran escala con privacidad diferencial enfrenta un trade-off entre privacidad, computación y utilidad. Un método común pero computacionalmente costoso implica ajustar modelos de lenguaje grandes en datos privados. Los enfoques basados en API existentes, como Aug-PE, dependen de prompts manuales y luchan con la utilización de información privada. El marco de trabajo CTCL propuesto genera datos sintéticos que preservan la privacidad sin necesidad de ajustar modelos de lenguaje masivos o requerir ingeniería de prompts extensiva. Utiliza un modelo ligero de 140 millones de parámetros, lo que lo hace adecuado para entornos con restricciones de recursos. CTCL condiciona la generación en información de tema para igualar las distribuciones de datos privados. A diferencia de Aug-PE, CTCL puede producir muestras de datos sintéticos ilimitadas sin costos de privacidad adicionales. Los experimentos muestran que CTCL supera a las líneas de base, particularmente bajo garantías de privacidad fuertes, demostrando su efectividad en capturar información útil. Los estudios de ablación confirman la importancia de la pre-entrenamiento y la condición basada en palabras clave para el rendimiento y escalabilidad de CTCL. La idea central de CTCL se puede extender a modelos más grandes para aplicaciones reales mejoradas.