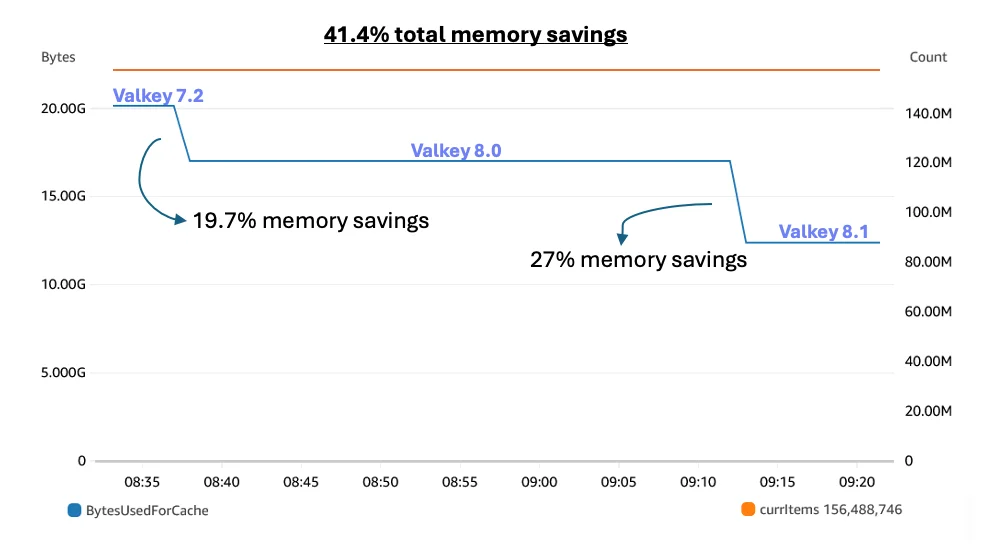
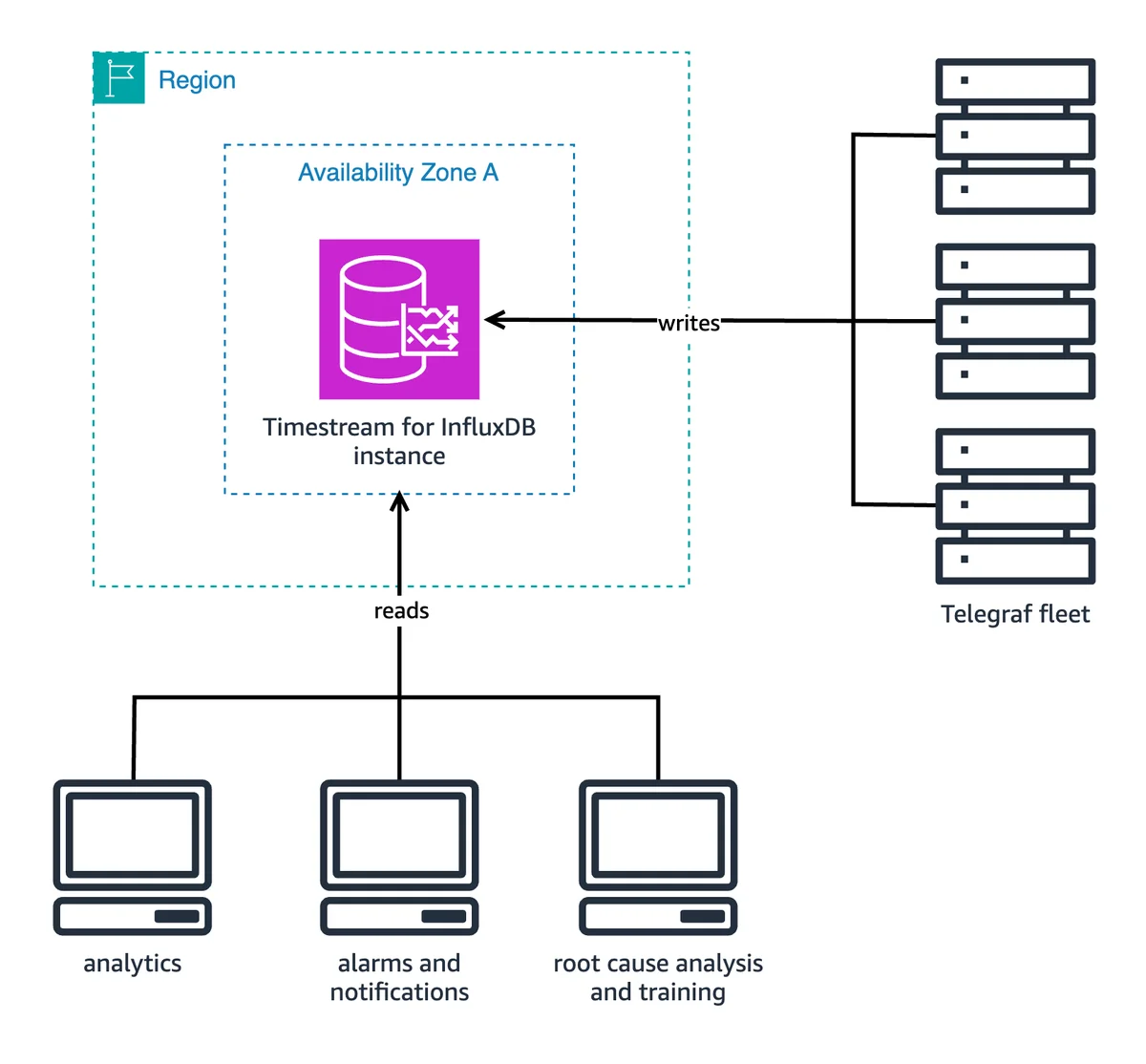
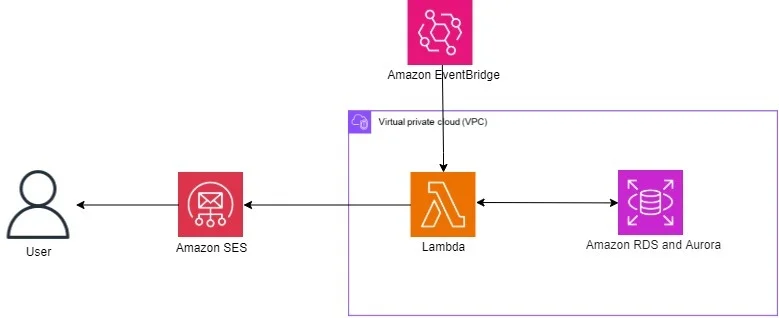
Blog de base de datos de AWS RSS Seguir
El sitio web ofrece un blog de Amazon Web Services (AWS) para bases de datos, que se esfuerza por ayudar a los usuarios a utilizar los servicios de bases de datos de AWS de manera eficiente, brindando tutoriales útiles, consejos y respuestas a preguntas frecuentes.