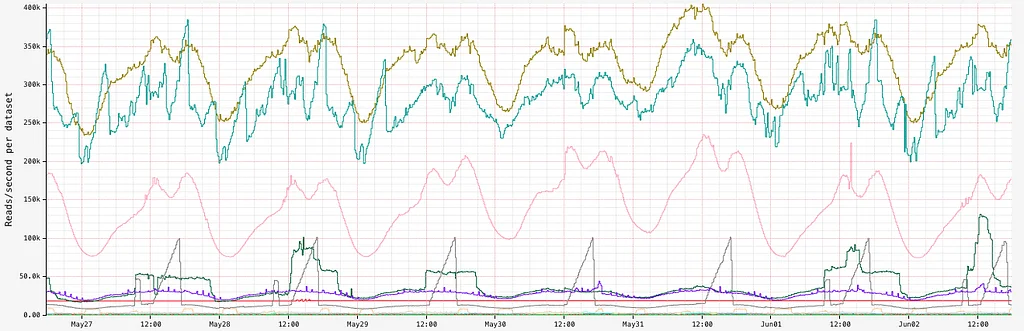
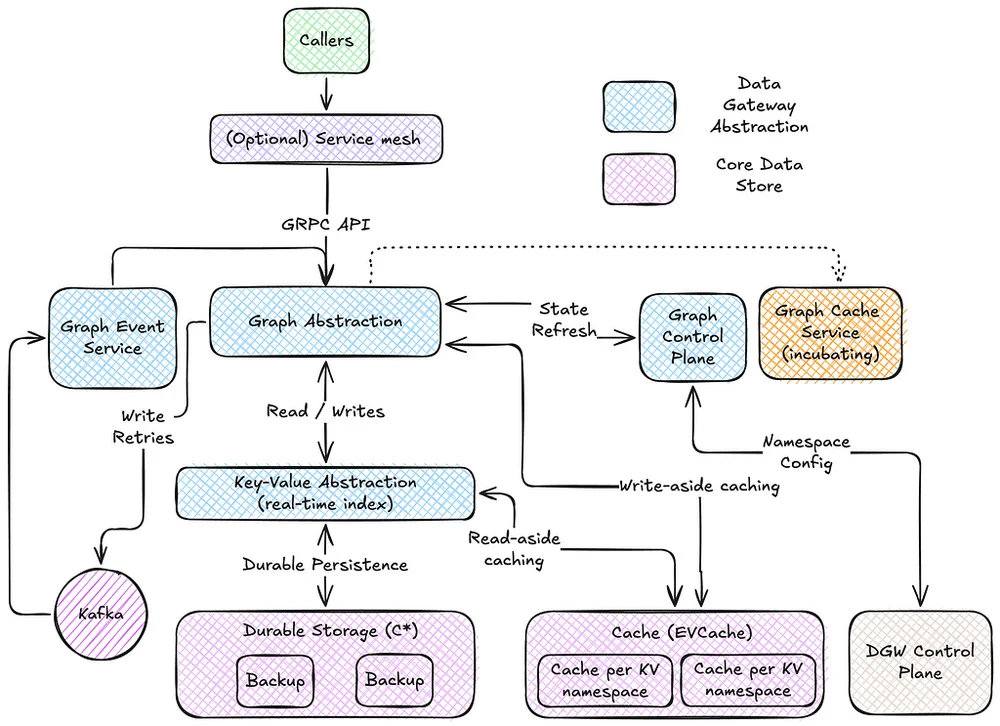
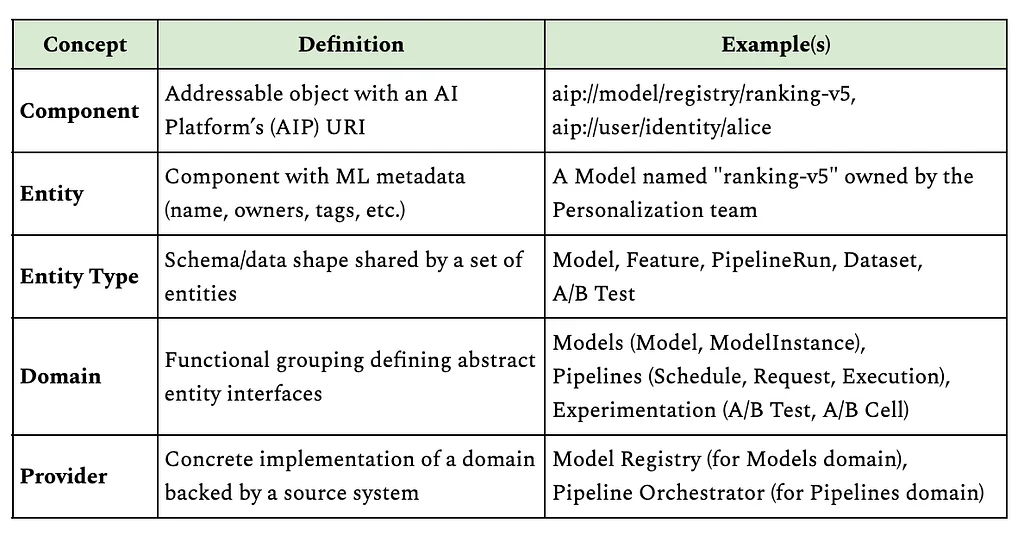
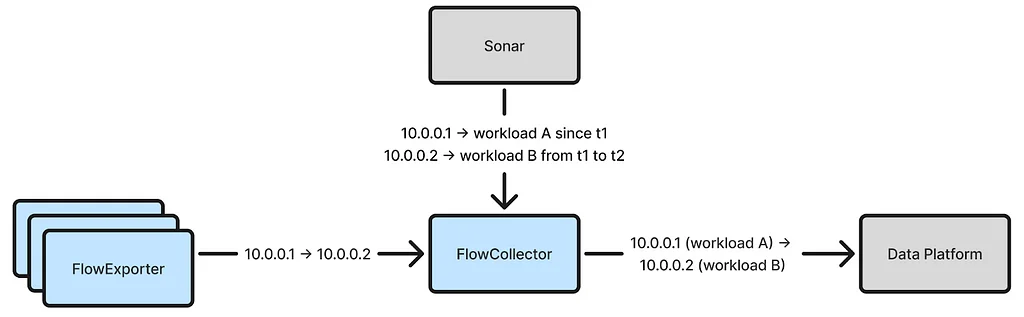
Netflix 使用 eBPF 捕获大规模 TCP 流日志以获取增强的网络见解,但准确地将流 IP 地址归因于工作负载身份是一个significant挑战。初始归因方法依赖于 Sonar,一个内部 IP 地址跟踪服务,但它由于分布式系统中的延迟和故障而导致了误归因。误归因使流数据不可靠,用于决策,并且在归因前等待 15 分钟的解决方法也无法消除该问题。为了解决这个问题,Netflix 开发了一种新的归因方法,该方法通过确定环境中的本地工作负载身份来归因本地 IP 地址。对于容器工作负载,Netflix 利用 IPMan,一个容器 IP 地址分配服务,来归因本地 IP 地址。一旦本地 IP 地址被归因,远程 IP 地址可以通过学习每个工作负载拥有的 IP 地址的时间范围来归因。FlowCollector 维护一个内存哈希表来表示这种知识,并使用 Kafka 与其他节点共享学习的时间范围。新的方法实现了准确的归因,并且可以优雅地处理暂时性问题,同时由于其简单性和内存查找也具有成本效益。该方法被扩展到归因跨区域 IP 地址,方法是将流转发到相应区域的节点。最后,该方法进一步扩展到归因非工作负载 IP 地址,如 Netflix 的内容交付网络所属的 IP 地址。