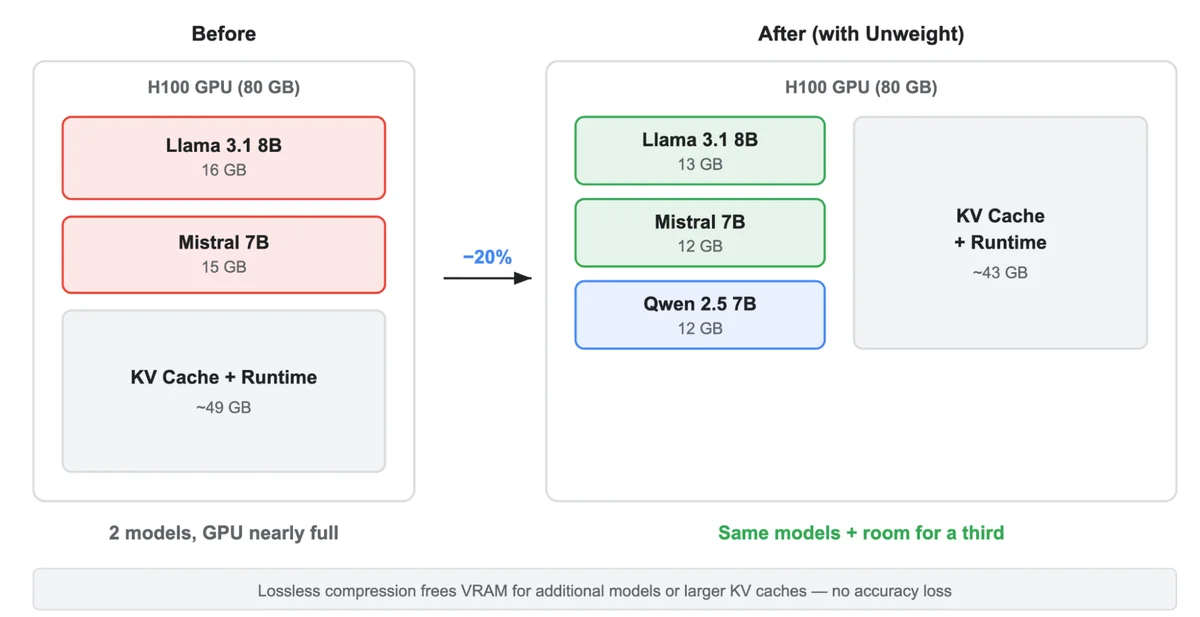
RSS Cloudflare 博客 关注 Unweight:如何在保持质量的前提下将大语言模型的参数量压缩 22% 在 Cloudflare 的网络上运行大语言模型(LLM),要求我们更智能、更高效地利用 GPU 内存带宽。为此,我们开发了 Unweight,这是一种无损推理时压缩系统,可将模型占用空间减少高达 22%,从而以前所未有的速度和成本提供推理服务。 Unweight: how we compressed an LLM 22% without sacrificing quality blog.cloudflare.com AI and ML News on Bluesky @ai-news.at.thenote.app bsky.app