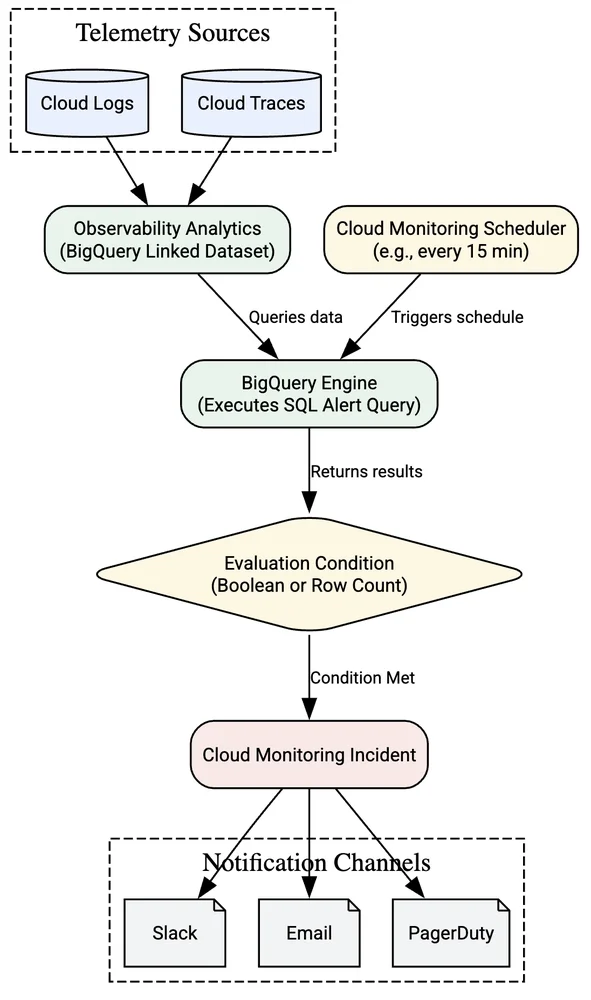
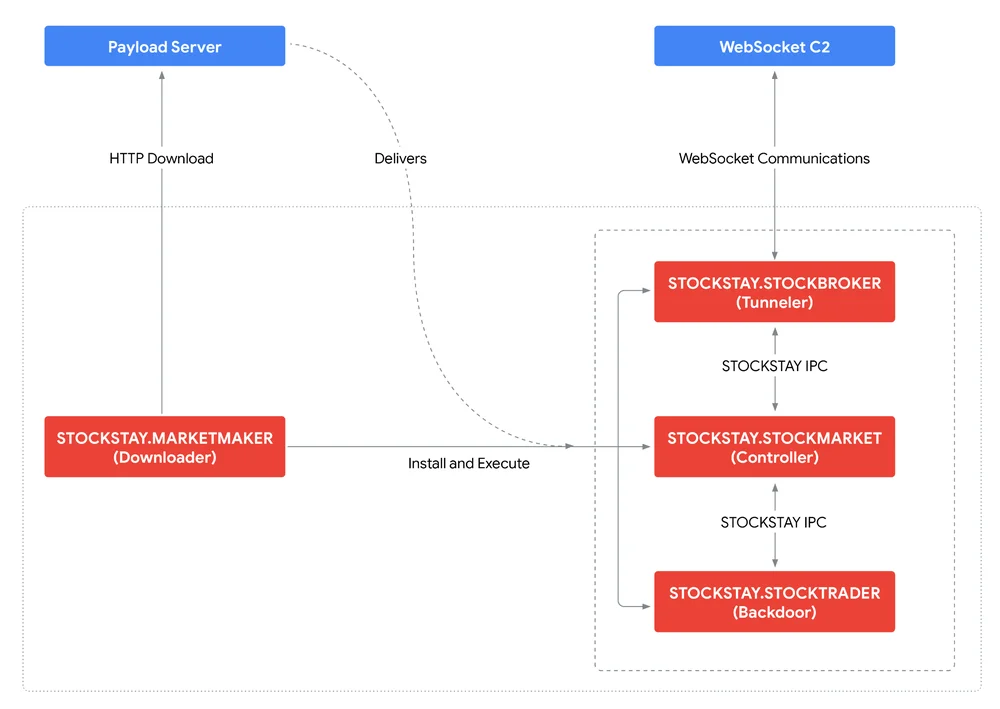
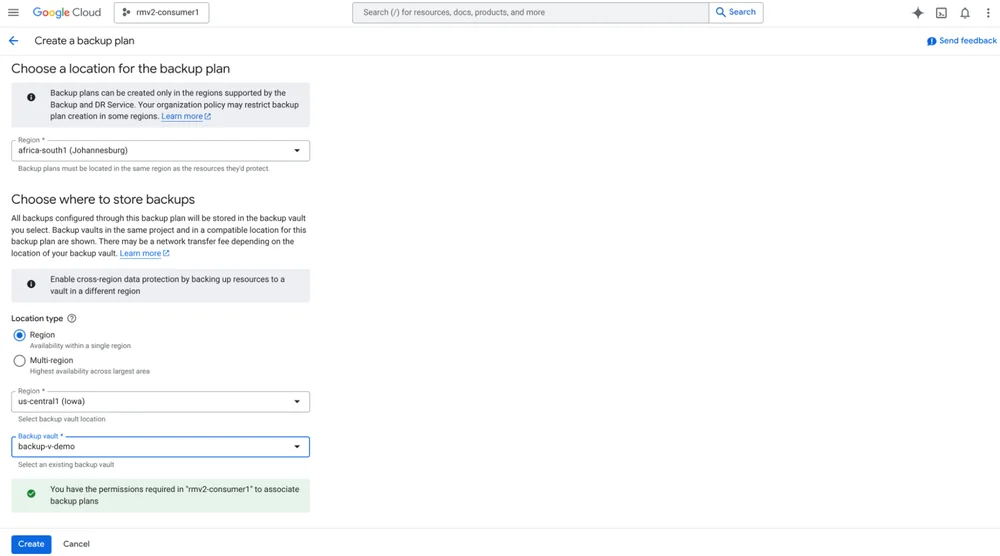
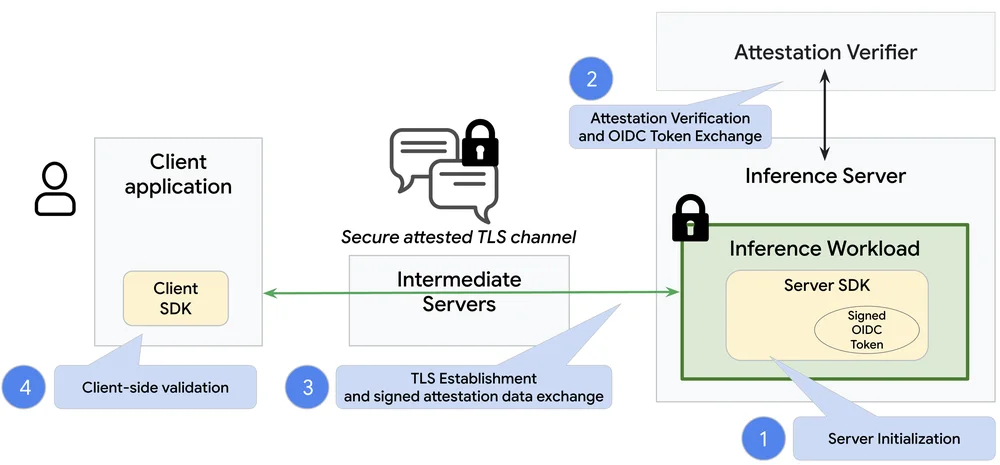
RSS クラウド ブログ フォロー
cloud.google.com/blogは、Google Cloudの公式ブログです。Google Cloudの製品とサービスのニュース、更新、洞察、クラウドコンピューティング業界のトレンドとイノベーションに関する情報を提供します。
このブログは、Google Cloudの専門家、エンジニア、思想リーダーが書いた記事で構成されており、人工知能、機械学習、データアナリティクス、セキュリティなど、広範囲のトピックをカバーしています。記事はしばしば技術的なチュートリアル、ケーススタディ、ベストプラクティスを含むため、Google Cloudを使用する開発者、ITプロフェッショナル、ビジネスリーダーにとって非常に有益なリソースです。
ブログは、トピック、製品、業界別にカテゴリー化されており、最新の記事を閲覧、特定のトピックを検索、RSSフィードにサブスクライブして最新のニュースと更新を追跡することができます。
ブログの主要な特徴として、以下のようなものがあります。
- Google Cloudの製品とサービスの詳細な記事、例えばGoogle Cloud Platform、Google Cloud Storage、Google Cloud AI Platform
- Google Cloudサービスの使用に関する技術的なチュートリアルとガイド
- Google Cloud顧客のケーススタディと成功事例
- 業界のトレンドとイノベーションに関する洞察と分析
- Google Cloudのパートナーシップと協力に関するニュースと更新
- Google Cloudの専門家と思想リーダーのインタビュー
総のところ、Google Cloudのブログは、クラウドコンピューティング、人工知能、関連技術に興味がある誰にとっても有益なリソースです。