超越数十亿参数的负担:解锁条件生成器的数据合成
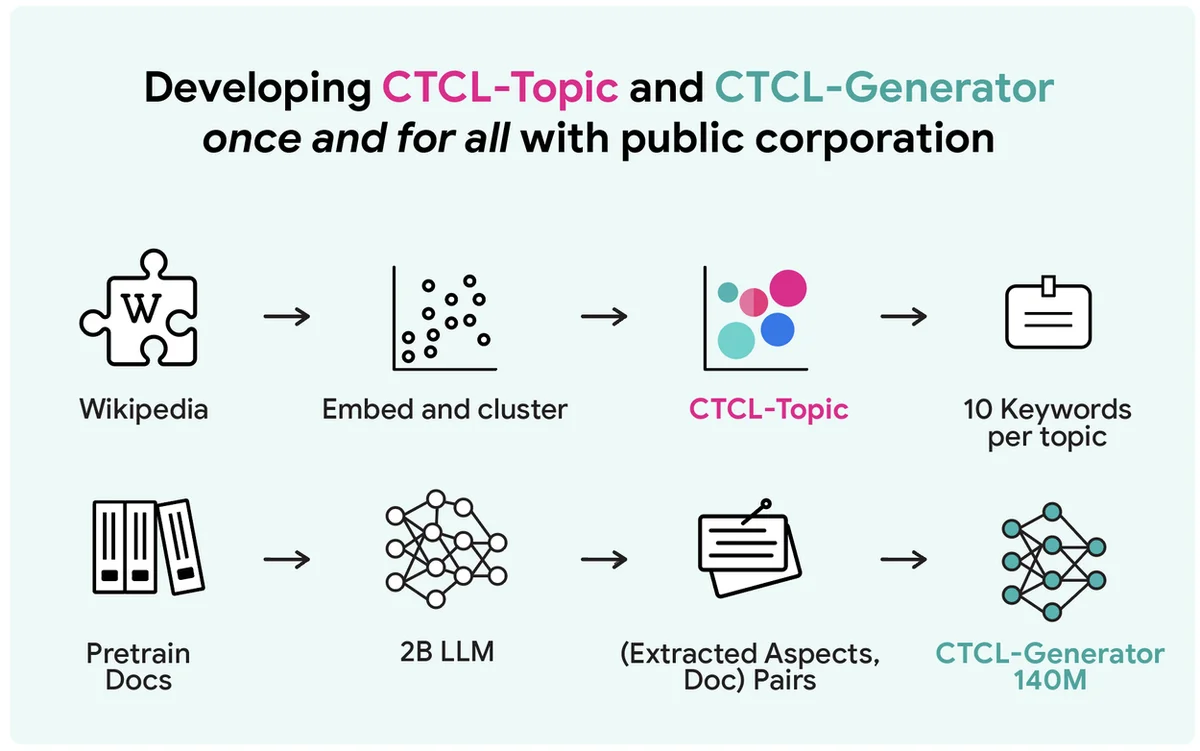
生成大规模差分隐私合成文本数据面临隐私-计算-效用权衡。一种常见但计算成本高昂的方法是使用私有数据对大型语言模型进行微调。Aug-PE 等现有的基于 API 的方法依赖于手动提示,并且在利用私有信息方面存在困难。提出的 CTCL 框架可以在不微调大型语言模型或进行大量提示工程的情况下生成隐私保护的合成数据。它使用了一个轻量级的 1.4 亿参数模型,使其适用于资源受限的环境。CTCL 根据主题信息进行条件生成,以匹配私有数据分布。与 Aug-PE 不同,CTCL 可以生成无限数量的合成数据样本,而无需额外的隐私成本。实验表明,CTCL 的表现优于基线方法,特别是在强隐私保证下,证明了其在捕获有用信息方面的有效性。消融研究证实了预训练和基于关键词的条件对于 CTCL 的性能和可扩展性的重要性。CTCL 的核心思想可以扩展到更大的模型,以改进现实世界的应用。