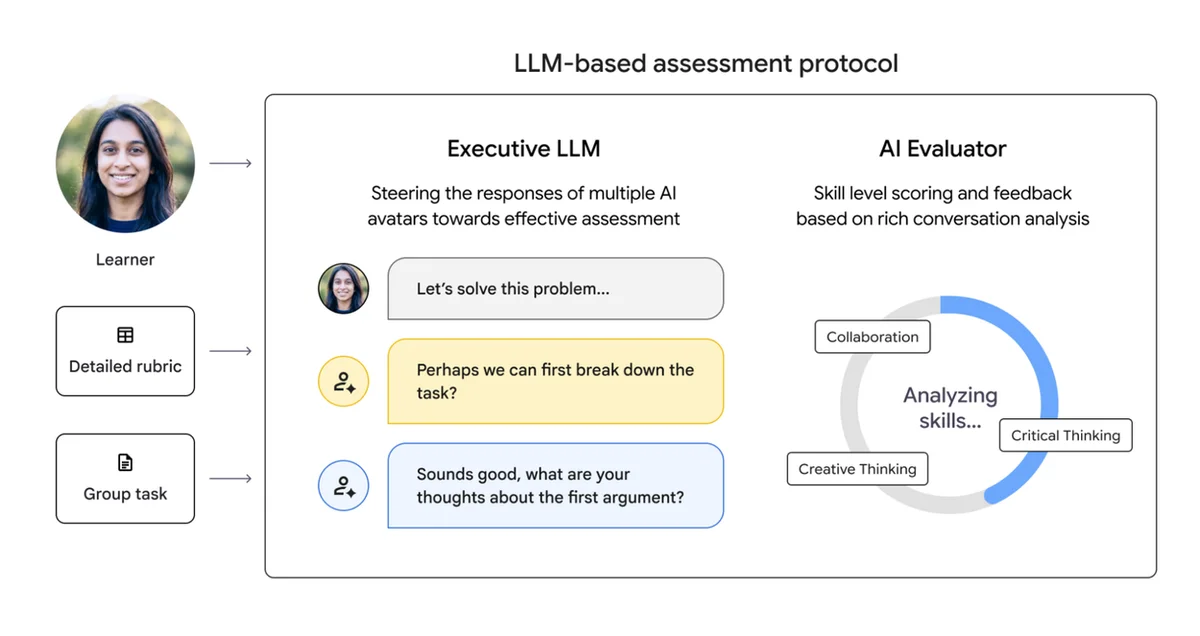
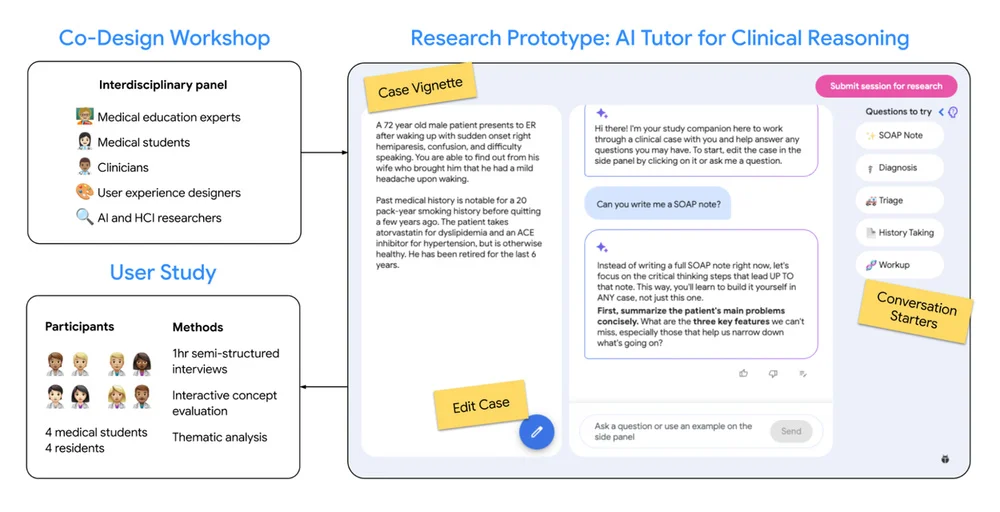
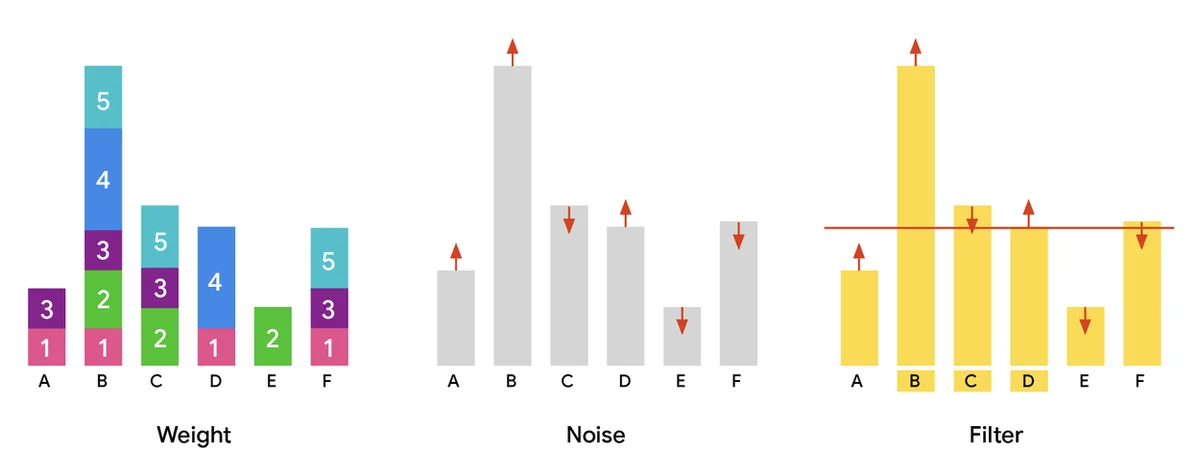
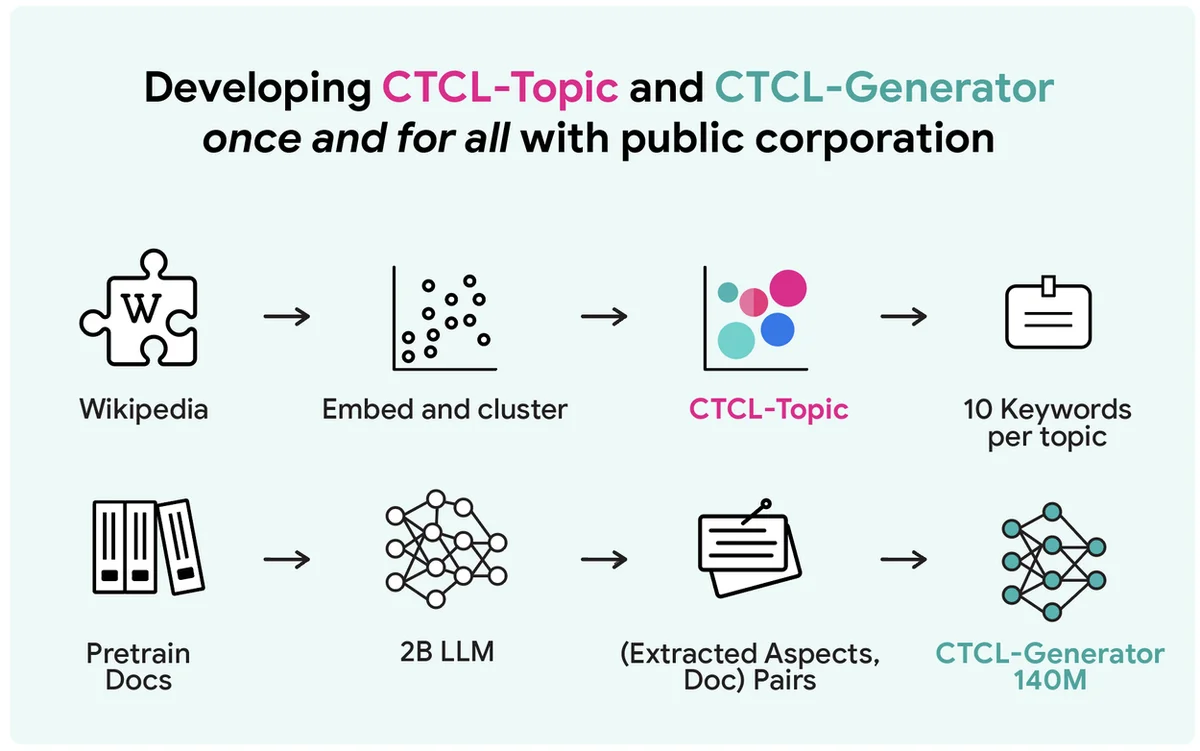
RSS Google人工智能博客 关注
Google Research是一个旨在与Google Research科学社区分享最新突破和见解的博客。该平台为研究人员与科学圈外的用户交流新兴技术、见解和创新提供了一个渠道,从人工智能和机器学习到医疗创新等各种科学主题。
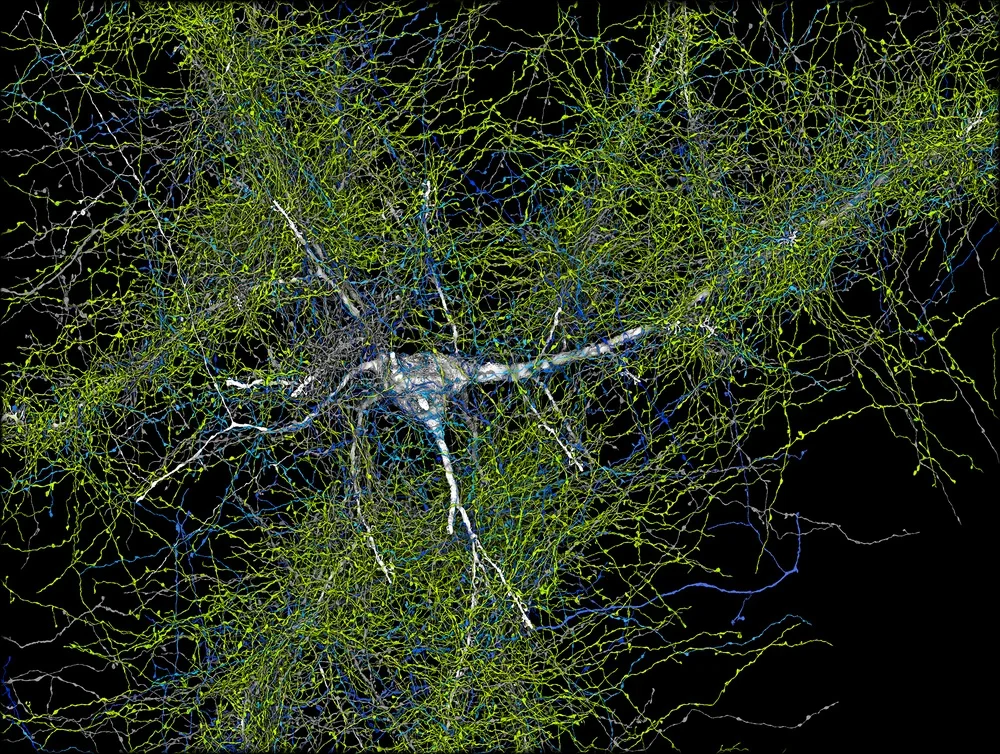
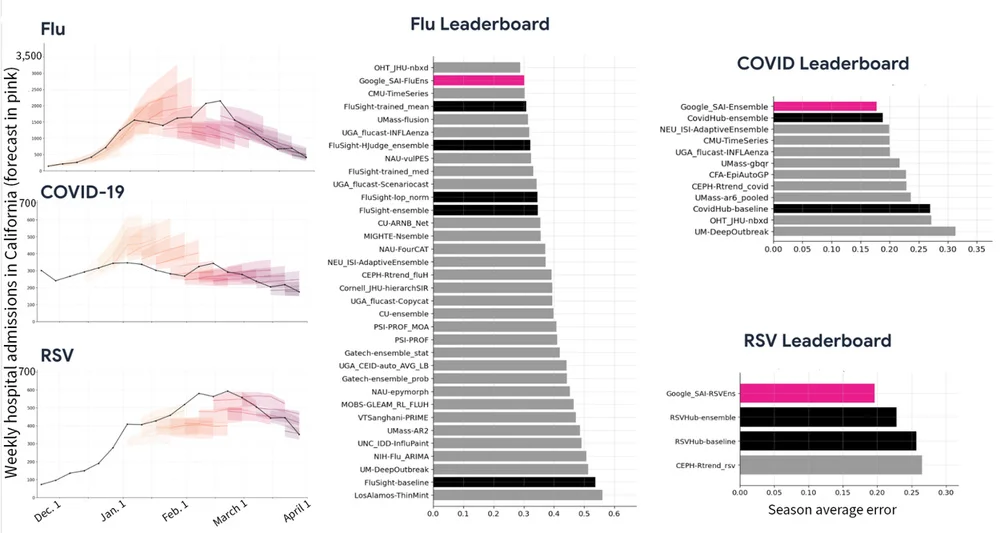
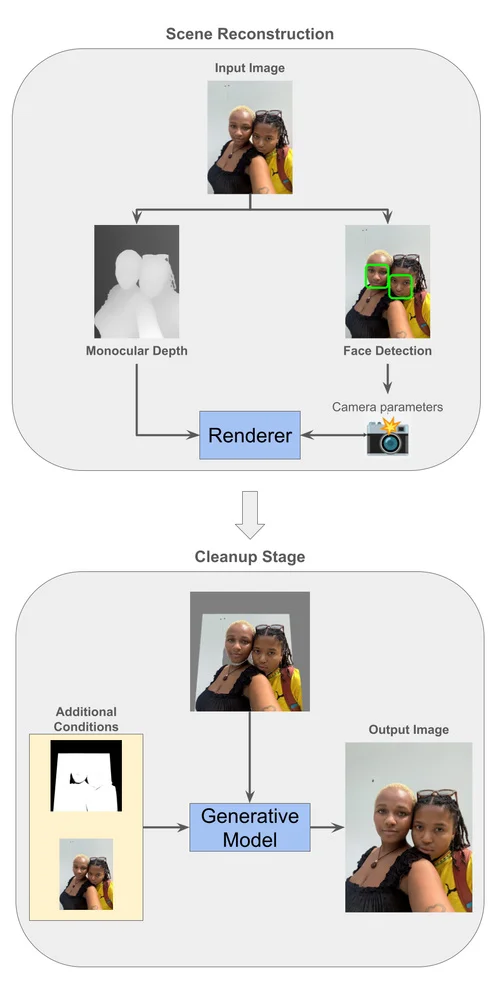
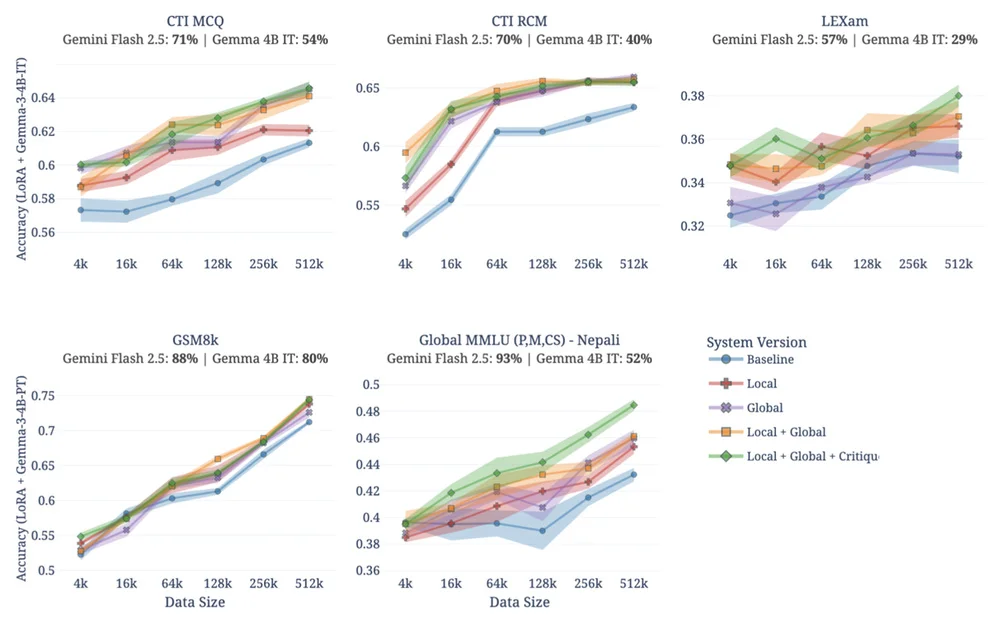
Google Research经常在博客上发表关于各种科学主题的文章,从人工智能和机器学习到医疗创新等。它还经常探讨新技术,从自动驾驶汽车到尖端医疗诊断和数据分析技术。
博客的一个显著特点是团队成员的贡献。Google的许多领先技术专家和研究人员都在博客上发表了有见解的文章,这些文章反映了他们多样化的兴趣和技能。该网站为用户提供了阅读最新技术和未来技术愿景的第一手账户。
博客还包括一个“作者”部分,允许用户访问个人贡献者的文章和见解。除了技术讨论和创新外,博客还涉及了与新技术相关的更广泛的社会和哲学问题,为用户提供了对技术如何影响我们日常生活的更全面的理解。
总之,Google Research博客提供了技术专长、研究突破和社会影响的独特结合,为技术爱好者、研究人员和任何对了解和塑造未来技术感兴趣的人都提供了一个宝贵的资源。