通过差分隐私分区选择实现大规模私有数据安全
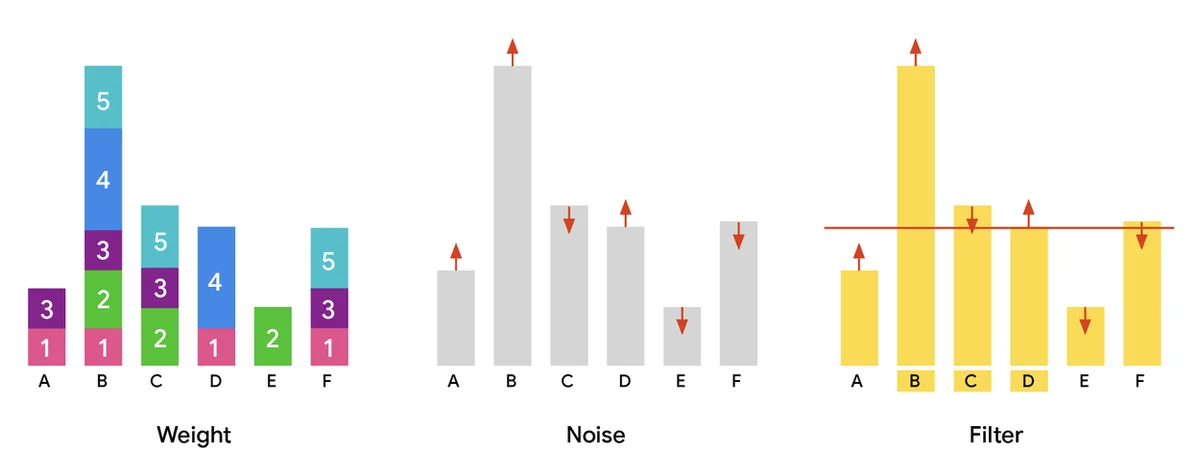
大型用户基于数据集对于AI进步、服务改进和个人化至关重要。分享这些数据集可以加速研究,但也存在隐私风险。差分隐私(DP)分区选择通过添加噪音来保护个人贡献,识别安全的公共数据子集。这对于词汇提取和私有数据分析等任务至关重要。处理大规模数据集需要并行算法,不仅是为了速度,还为了处理庞大的规模。我们的出版物《可扩展的私有分区选择通过自适应加权》引入了一种高效的并行算法用于DP分区选择。该算法可以扩展到数百亿个项目,远远超过之前的能力。我们的目标是最大化所选项目,同时保护用户隐私,优先考虑流行的数据。标准方法涉及加权、添加噪音和根据阈值过滤项目。我们的新型自适应加权算法MAD将流行项目的“过剩权重”重新分配给隐私阈值以下的项目。这提高了实用性,包括更多项目,而不牺牲隐私或可扩展性。实验表明,我们的两次迭代MAD算法实现了最新的结果,输出的项目比其他方法多,而具有相同的隐私保证。我们正在开源我们的算法,以促进社区创新。