实现 Pinterest 基础模型的近线性训练可扩展性
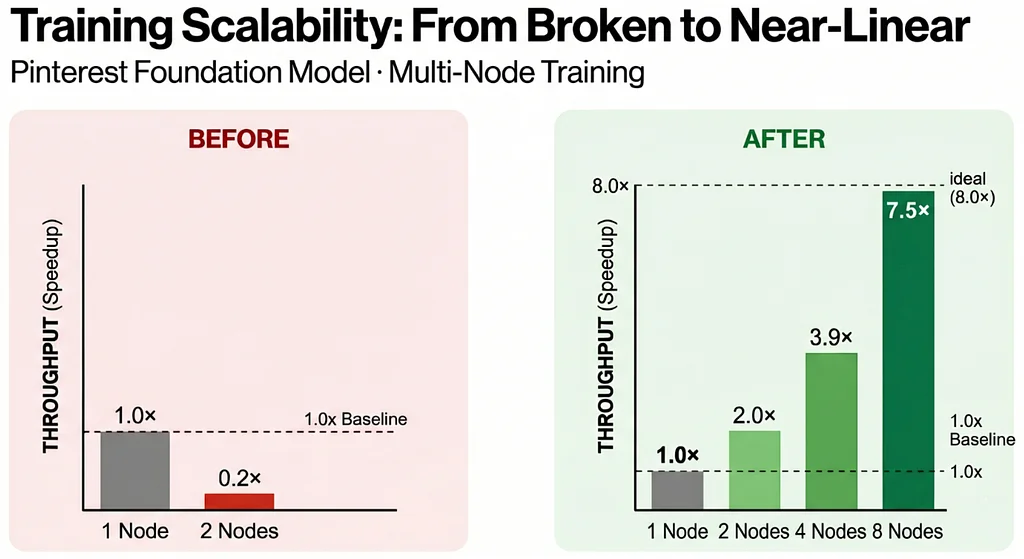
Pinterest 的基础模型对其推荐系统至关重要,每日影响数百万用户。最初,这些大模型的分布式多节点训练效果不佳,增加机器数量反而大幅拖慢训练进程。即便采用 AWS Elastic Fabric Adapter(EFA)以提升网络性能,扩展效率依然低下。性能分析显示,分布式嵌入查找造成了严重的通信瓶颈,GPU 因等待数据而闲置。团队实施了多项优化以解决这一通信开销问题:量化通信(QComms)通过压缩嵌入张量减少了数据负载;均衡分片改善了 GPU 间的工作负载分布;带宽感知的嵌入优化将嵌入维度减半,从而降低数据移动量。关键突破在于实现二维并行性,最初针对 AllReduce 进行优化,提升了本地通信效率。随后,团队将二维并行性的拓扑结构翻转,以优化 All-to-All 通信,将昂贵操作保留在节点内部,并利用成本较低的 AllReduce 进行跨节点同步。这一改进实现了接近线性的扩展性能:2 节点时达到 2.0 倍,4 节点时达到 3.9 倍,8 节点时更是达到令人瞩目的 7.5 倍扩展。这些进展使得训练更大规模的模型成为可能,从而显著提升了 Pinterest 推荐界面中的用户参与度,并加快了实验迭代周期。