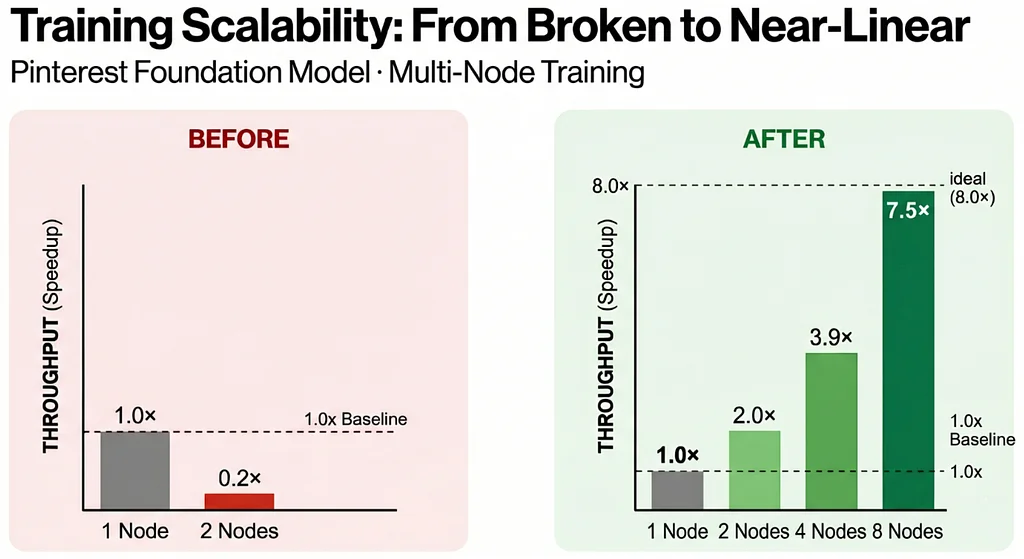
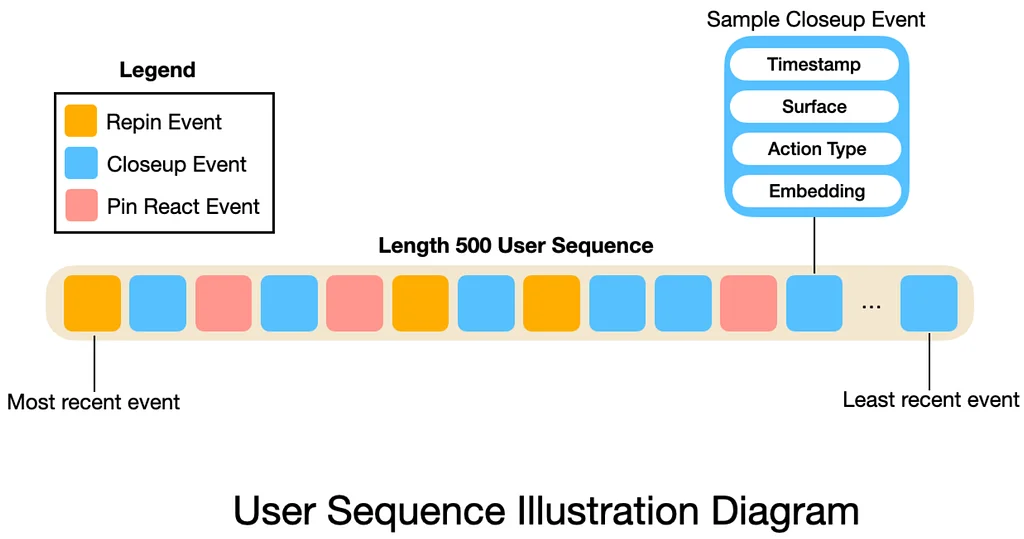
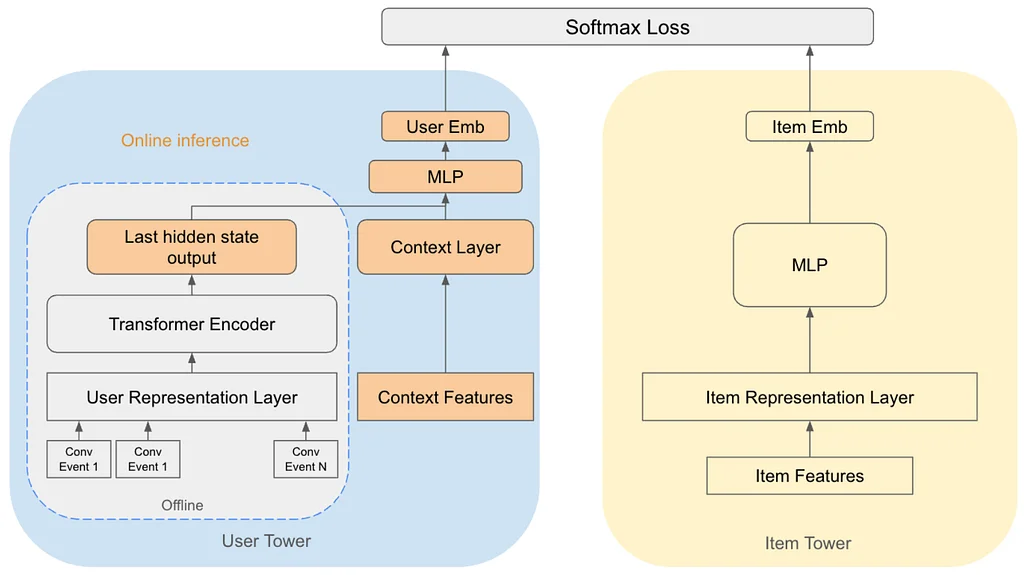
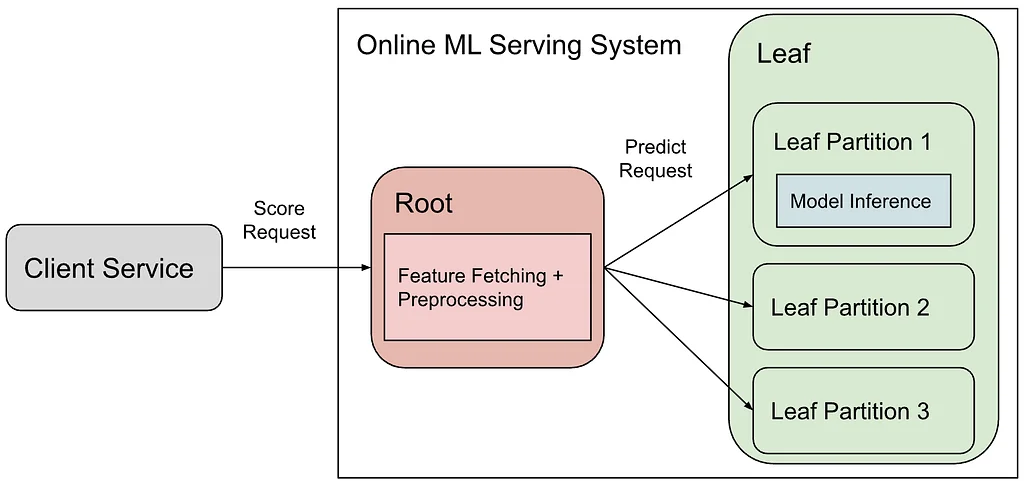
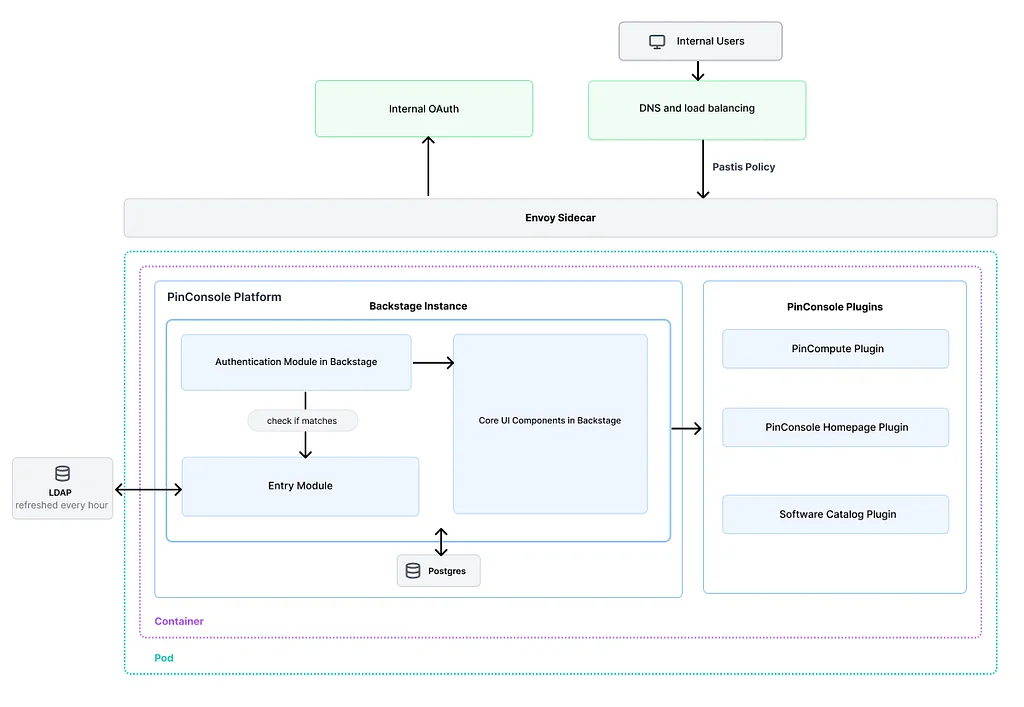
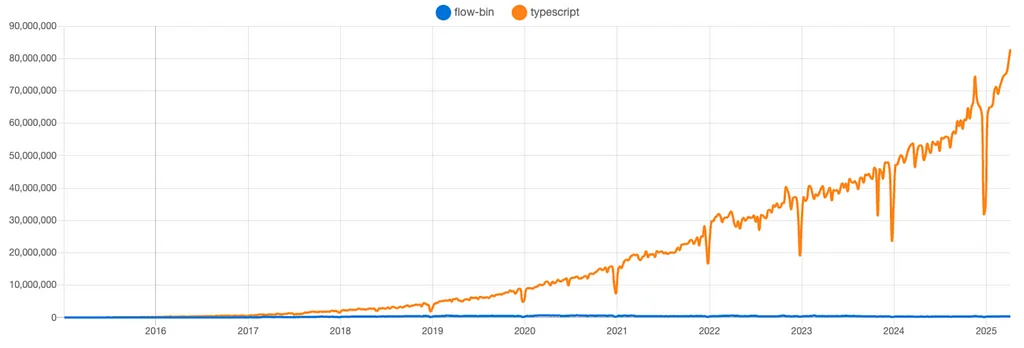
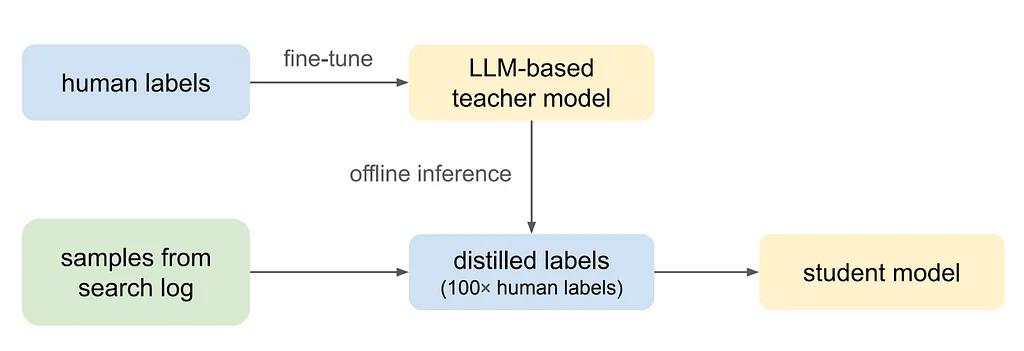
Medium 上 Pinterest 工程团队的 RSS 故事 关注
Medium 上的 Pinterest 工程展示了推动流行视觉发现平台的技术创新。通过深入的文章,工程师们分享了他们在可扩展性、机器学习、数据基础设施等方面的工作见解。该出版物强调了 Pinterest 的工程文化,强调协作、实验和解决复杂问题的热情。读者可以探索诸如构建推荐系统、优化搜索功能和开发数据分析工具等主题。内容为工程师和技术爱好者提供了宝贵的视角,了解像 Pinterest 这样的大型平台的技术细节。无论是深入研究图像识别的挑战还是他们基础设施的演变,Medium 上的 Pinterest 工程都为人们提供了一个迷人的技术视角。