优化机器学习工作负载网络效率(第一部分):特征修剪器
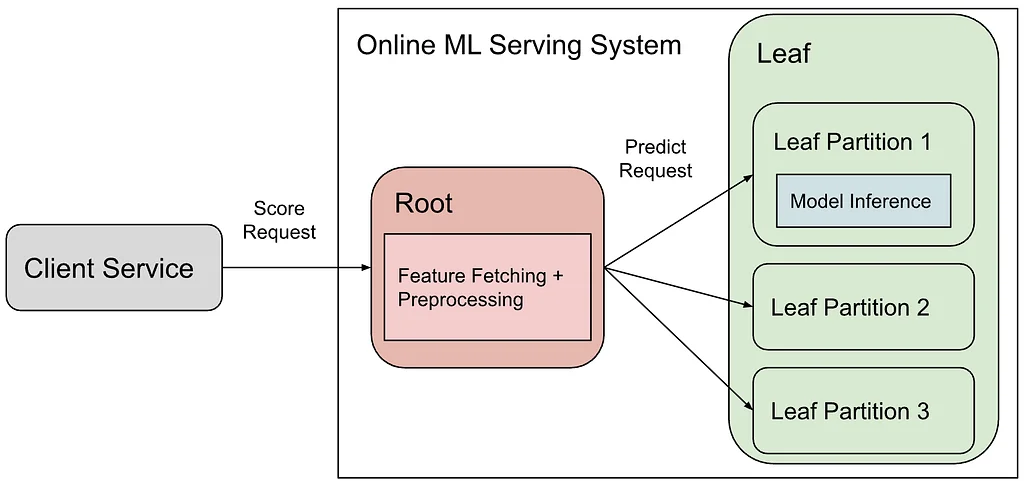
Pinterest 的在线机器学习(ML)服务系统采用根 - 叶架构,客户端服务通过该架构请求 Pin 的预测分数。根组件负责特征检索与预处理,而叶节点执行模型推理,通常利用 GPU。该设计简化了新模型的接入流程,并通过分离 CPU 与 GPU 工作负载优化资源利用率。然而,由于传递大量特征,根与叶分区之间出现了网络瓶颈。最初,系统实施了 lz4 压缩以减少网络用量,虽显著节省了带宽,但导致 CPU 使用率和延迟略有上升。这虽是一个良好的开端,但核心问题——传输不必要的特征——依然存在。随后,团队开发了“按需发送”(Send What You Use)方案,仅发送特定模型所需的特征,以解决这一问题。模型签名(model signature)定义了模型的输入与输出,是特征需求的权威来源。模型在训练并导出时,其签名会一同保存。Leaf 节点加载这些签名,构建特征转换器,仅处理必要特征。为同步根与叶之间的特征需求,模型签名被发布为轻量级工件(artifacts)。这些签名被聚合为包级映射(bundle-level mappings),随后与现有配置一同部署至根节点。该部署流程遵循与模型发布相同的分阶段交付机制,确保一致性并支持优雅回滚。此集成使得 Feature Trimmer 能够动态更新根节点上的特征白名单,确保仅传输必要特征。系统通过版本化查找和降级机制,处理频繁模型更新与渐进式发布,确保根节点对所需特征的视图与实际部署在叶节点上的模型保持同步。通过剪枝不必要的特征,Pinterest 显著降低了网络流量并提升了基础设施效率。