使用大型语言模型改进 Pinterest 搜索相关性
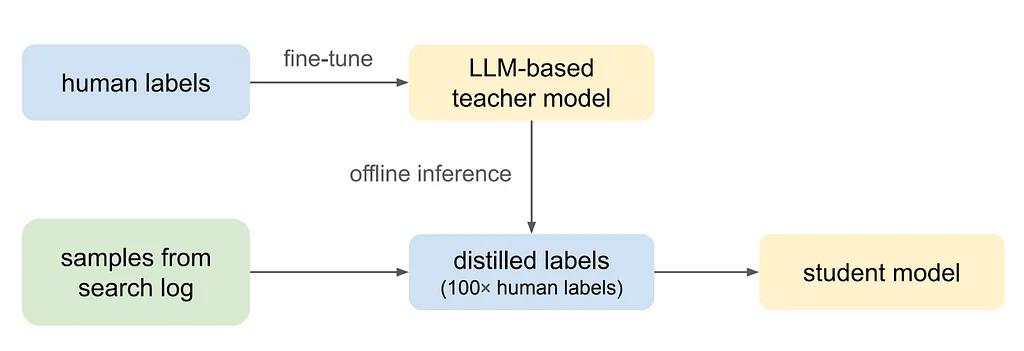
Pinterest 搜索是用户可以发现与他们的信息需求相符的启发性内容的关键入口,搜索相关性衡量搜索结果与搜索查询的匹配程度。为了改进搜索相关性模型,我们使用一个 5 级准则来衡量查询和 Pins 之间的相关性。我们使用交叉编码器语言模型来预测 Pin 与查询的相关性,同时结合 Pin 文本,并将任务表述为多类别分类问题。该模型使用人工标注的数据进行微调,最小化交叉熵损失。为了表示每个 Pin,我们使用了一系列不同的文本特征,包括 Pin 的标题和描述、合成的图像标题、高参与度的查询词、用户策划的板块标题以及链接标题和描述。然而,基于交叉编码器 LLM 的分类器由于实时延迟和成本的考虑,难以在 Pinterest 搜索中进行扩展。因此,我们使用知识蒸馏将基于 LLM 的教师模型蒸馏成一个轻量级的学生相关性模型。学生模型使用查询级特征、Pin 级特征和查询-Pin 交互特征来预测 5 级相关性分数。我们采用知识蒸馏和半监督学习来训练学生模型,这有效地利用了大量最初未标记的数据,并将数据扩展到世界范围内的多种语言。离线实验证明了每个建模决策的有效性,包括语言模型的比较、丰富文本特征的重要性以及通过蒸馏扩大训练标签规模。在线结果显示,搜索 feed 相关性提高了 +2.18%(通过 nDCG@20 衡量),并且在全球范围内搜索完成率显着提高。所提出的相关性建模流程有效地推广到训练期间未遇到的语言,而基于多语言 LLM 的相关性教师模型则推广到未见的语言。未来的工作将探索整合可服务的 LLM、视觉与语言多模态模型以及主动学习策略,以动态扩展和提高训练数据的质量。