AWS Machine Learning Blog 中文 关注 提供的 URL 是 Amazon Web Services (AWS) 机器学习博客。该 AWS 网站部分展示了关于机器学习技术的文章和更新、如何使用 AWS 以及机器学习在实际应用和用例中的应用。这些博客旨在帮助开发者、科学家和工程师了解如何利用机器学习来执行各种任务,如预测分析、自然语言处理和计算机视觉等。此博客部分还讨论了机器学习领域中的新兴趋势和如何将其与 AWS 服务集成。 RSS aws.amazon.com AWS Machine Learning Blog aws.amazon.com
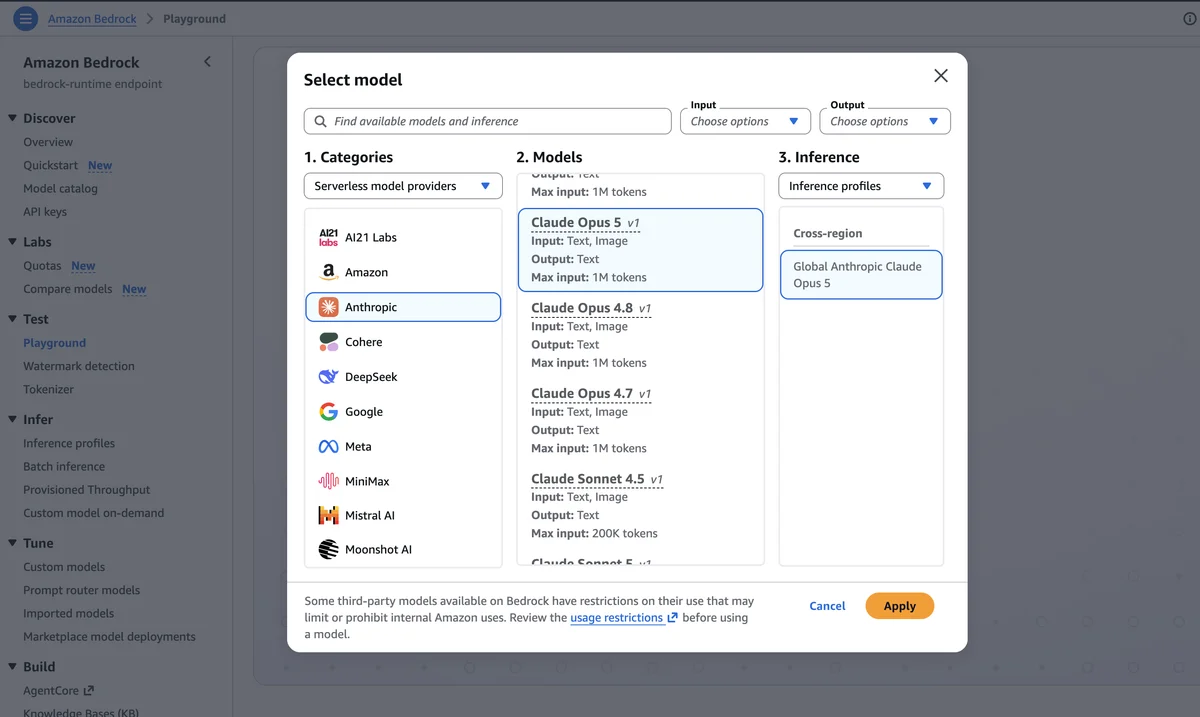
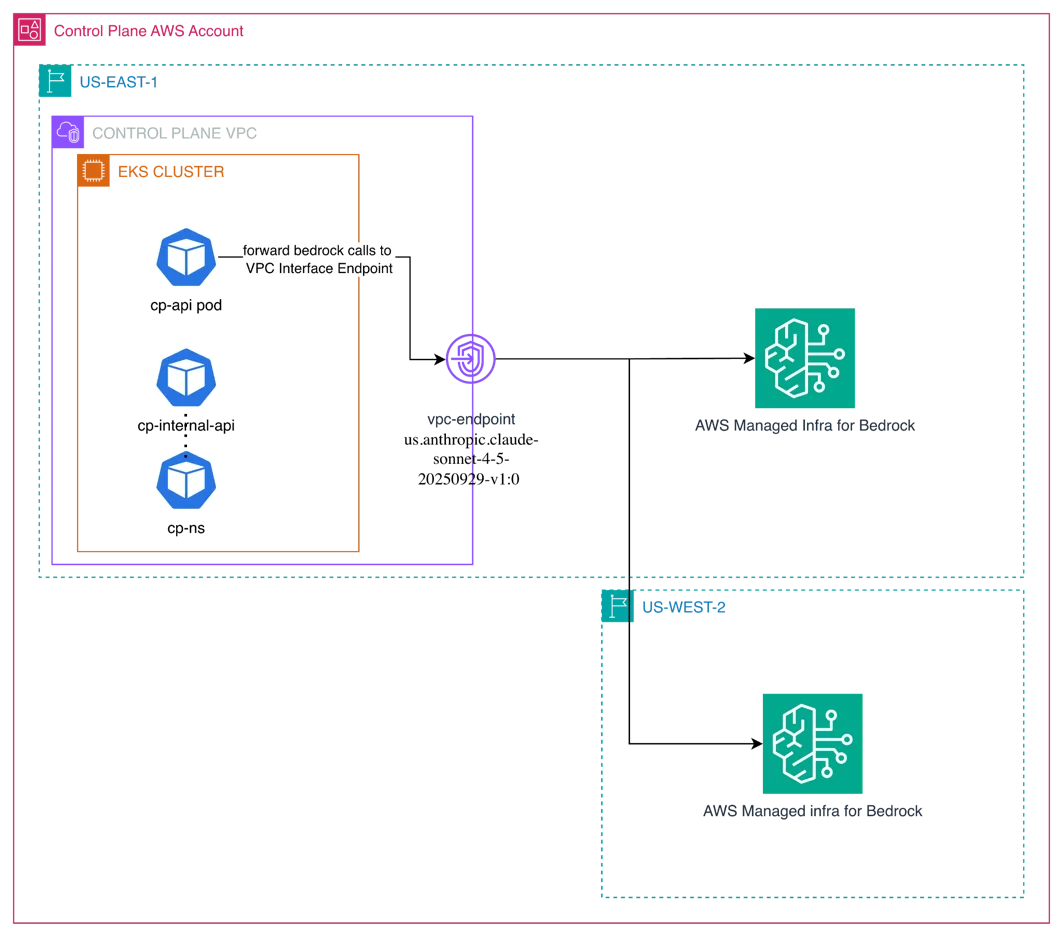
在 AWS 推出 Claude Opus 5:Anthropic 能力最强的 Opus 模型 本文介绍 Opus 5 的改进内容,并为将模型集成到代理系统以及在 Amazon Bedrock 上进行生产推理工作的 AI 工程师提供实用指导。请参阅 AWS 上的 Claude Platform 文档。 Introducing Claude Opus 5 on AWS: Anthropic’s most capable Opus model aws.amazon.com
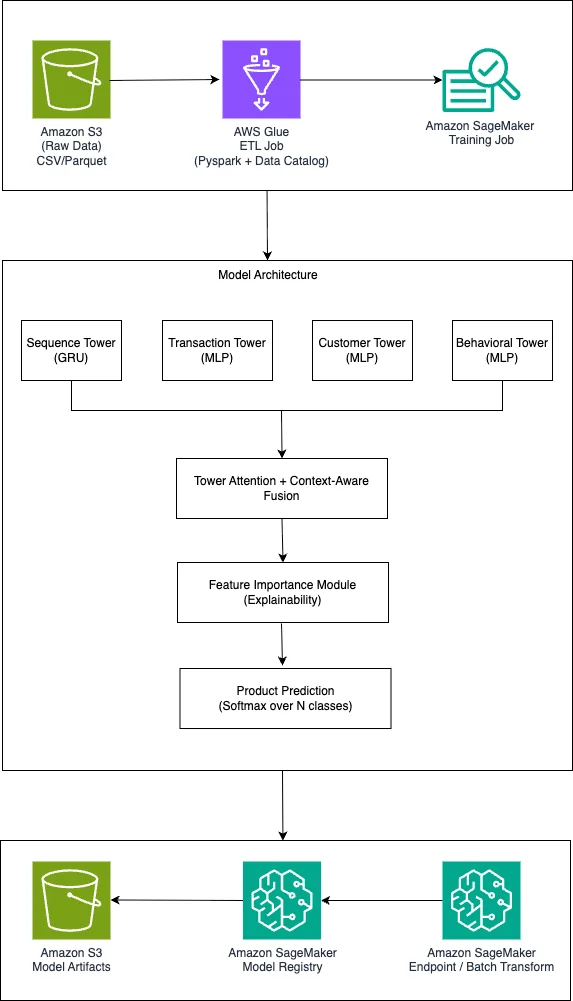
在 AWS 上构建可解释的银行最佳产品推荐系统 学习构建基于 Amazon SageMaker AI 和 PyTorch 的可解释“下一个最佳产品”推荐系统的架构与设计决策。该系统采用带有学习到的注意力机制的多塔神经网络,在提供精准的客户级推荐的同时,满足银行监管机构对可解释性的要求。 Build an explainable next-best-product recommendation system for banking on AWS aws.amazon.com
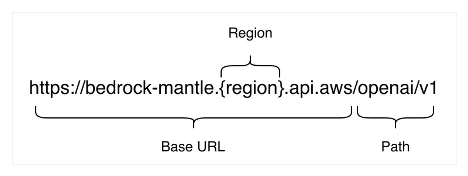
在 Amazon Bedrock 上开始使用 OpenAI GPT-5.6 Sol、Terra 和 Luna OpenAI GPT-5.6 Sol、Terra 和 Luna 现已在 Amazon Bedrock 上普遍可用。了解如何选择模型、通过 bedrock-mantle 端点上的 Responses API 运行推理、利用提示缓存降低成本、连接 OpenAI Codex 编码代理,以及规划配额与扩展。 Get started with OpenAI GPT-5.6 Sol, Terra, and Luna on Amazon Bedrock aws.amazon.com
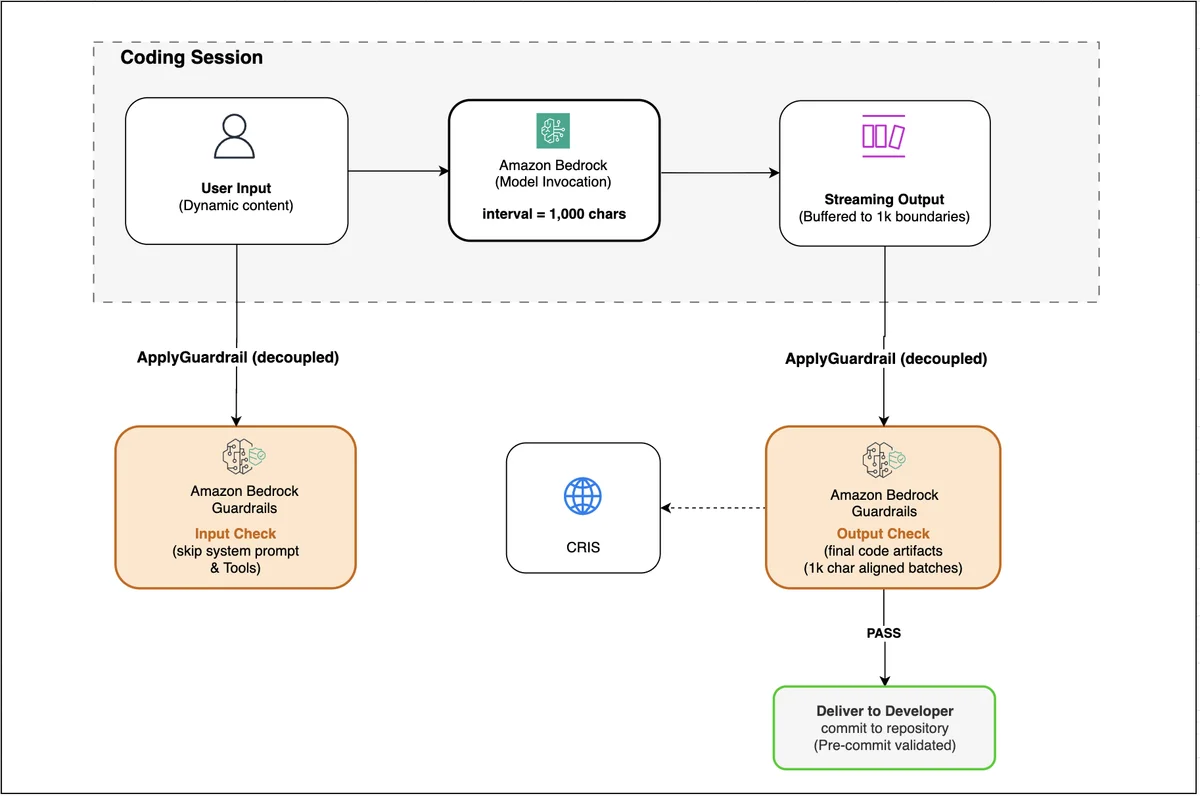
将 Amazon Bedrock Guardrails 应用于代码生成工作流的最佳实践 在本文中,我们介绍如何为代码生成工作流配置 Amazon Bedrock Guardrails,以配合编程助手克服这些限制。借助这些最佳实践,您可以构建一个高效的蓝图,协助您进行有效的容量规划,并实现稳健的安全覆盖。 Best practices for applying Amazon Bedrock Guardrails to code generation workflows aws.amazon.com
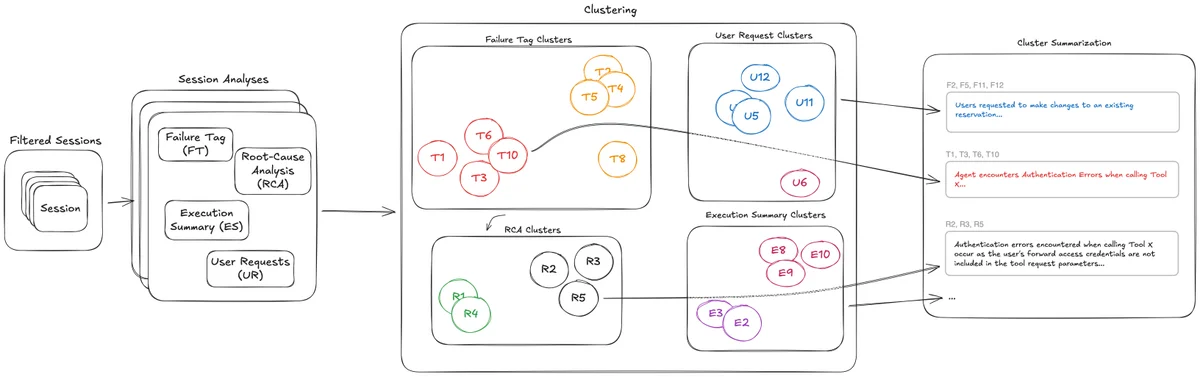
评估 AI 智能体:基于 Strands 和 AgentCore 的生产蓝图 Motorway 与 AWS 共同构建了一条端到端的评估流水线,将错误结果率从每 8 次查询中出现 1 次降低至每 50 次查询中出现 1 次,并将问题检测时间从数小时缩短至数分钟。该流水线结合了 Strands Agents SDK 与 Amazon Bedrock AgentCore,后者是一项完全托管的服务,用于大规模部署和运营 AI 代理。在本篇博客中,您将学习如何为自己的代理构建此流水线。 Evaluating AI Agents: A production blueprint with Strands and AgentCore aws.amazon.com
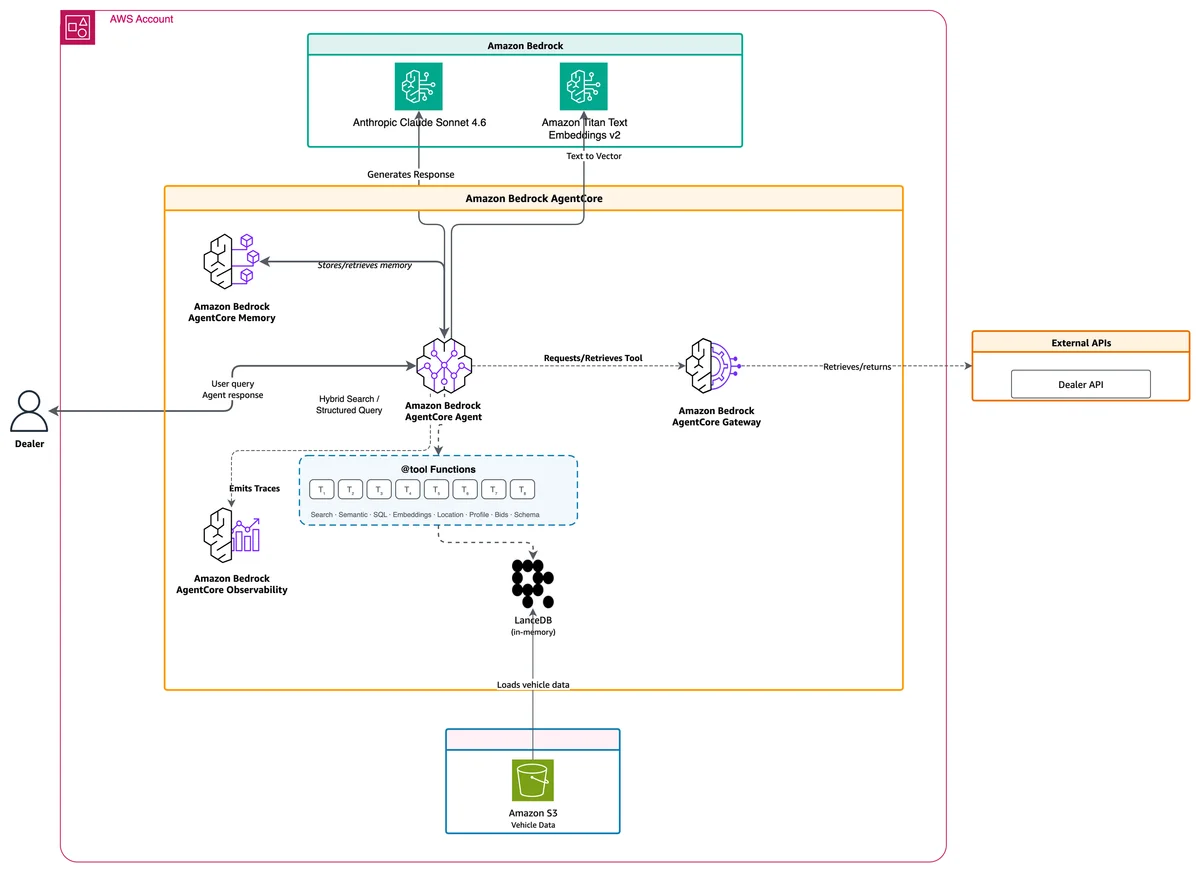
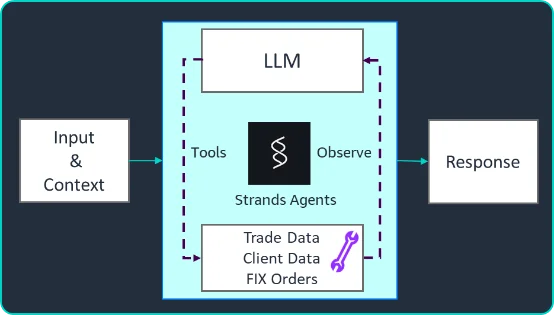
构建交易助理:Jefferies 如何利用 AI 优化前台交易运营 在本文中,我们探讨 Jefferies 如何利用基于 Strands Agents 的解决方案克服这些挑战。Strands Agents 是一款用于构建 AI 代理的代理编排 SDK,该代理能够通过编排对基础模型(FMs)和外部工具的调用,实现推理、规划和行动。该解决方案采用大语言模型(LLMs)、Amazon Bedrock 以及 Amazon Bedrock Knowledge Bases。此外,该方案还采用了模型上下文协议(Model Context Protocol, MCP),这是一种开放标准,有助于 AI 代理通过统一接口安全地连接到多样化的数据源和工具。我们将介绍该解决方案的概述、选择底层技术栈的理由、经验教训,以及该解决方案为 Jefferies 带来的业务影响。 Building trade assistant: How Jefferies optimized front office trading operations with AI aws.amazon.com
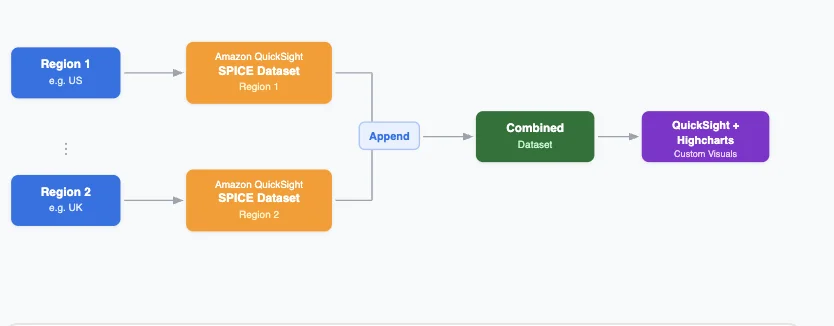
使用 Highcharts 在 Amazon Quick 中构建多区域可视化 本文介绍如何在 Amazon QuickSight 中利用 Highcharts 自定义可视化构建多区域运营商性能仪表板,以克服原生图表的局限性。您将学习如何在创建统一可视化的同时,通过 QuickSight 联合数据集功能实现跨 AWS 区域的数据主权。该解决方案包含生产就绪的图表配置,并满足安全、合规性和可扩展性要求。 Building multi-Region visualizations with Highcharts in Amazon Quick aws.amazon.com
使用 Amazon Bedrock AgentCore 优化检测静默代理故障 Amazon Bedrock AgentCore 优化功能可揭示生产环境中 AI 代理的隐性行为故障:那些通过所有健康检查但仍产生错误结果的故障。了解洞察功能如何跨会话发现、解释并排序故障模式,以便您优先解决影响最大的问题。 Detecting silent agent failures with Amazon Bedrock AgentCore optimization aws.amazon.com
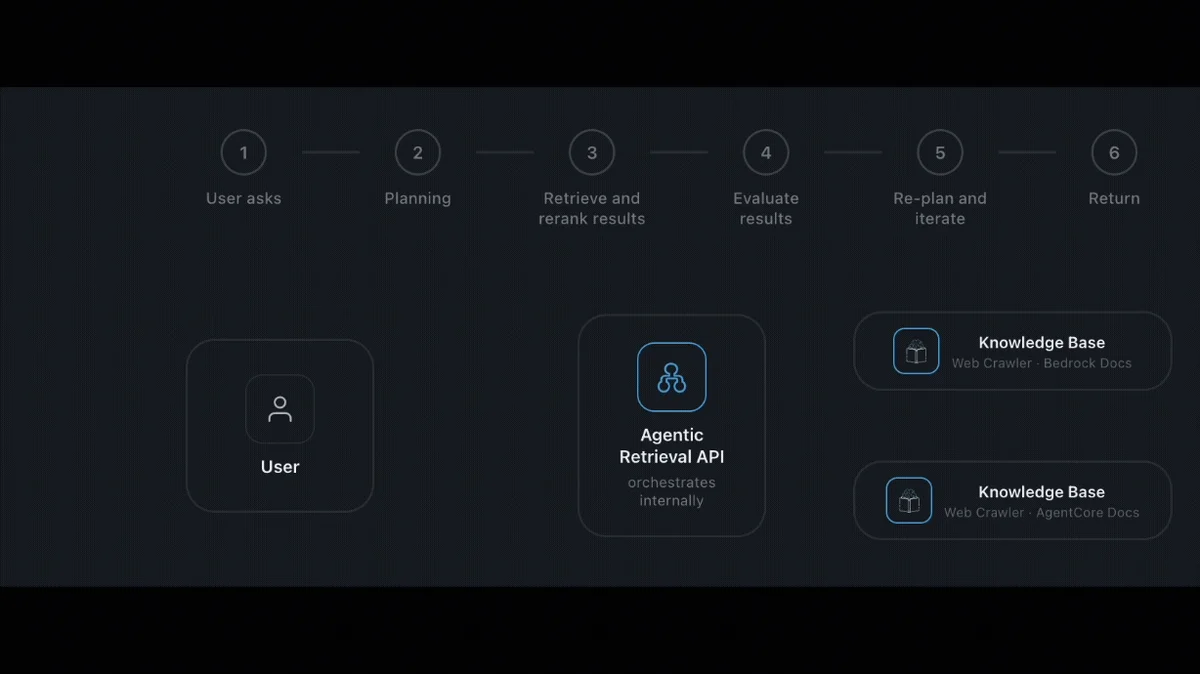
用于 Amazon Bedrock 托管知识库的代理检索 本文重点探讨经典检索在处理多部分问题时的局限性,介绍 AgenticRetrieveStream API 的工作原理(包括请求构建和追踪解析),以及何时应选用它而非标准检索 API。 Agentic retrieval for Amazon Bedrock Managed Knowledge Base aws.amazon.com
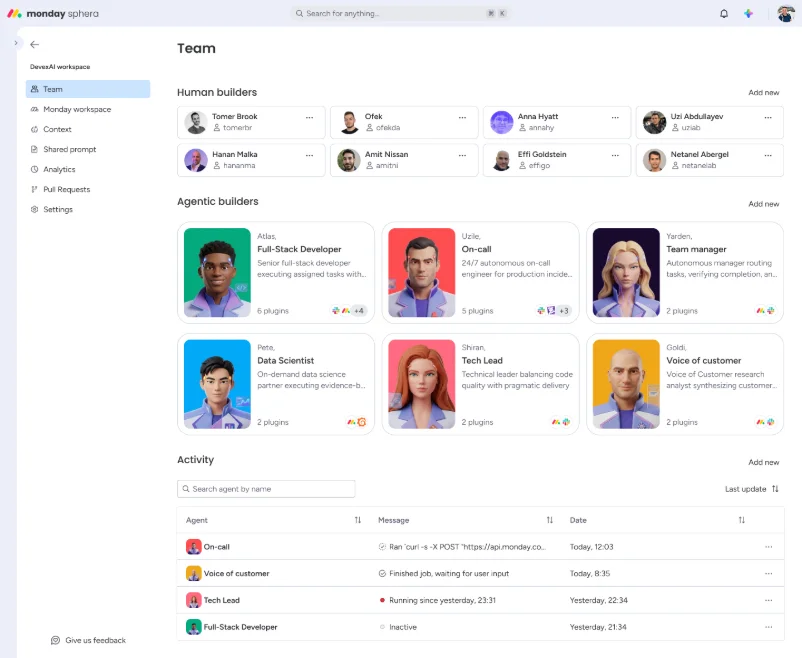
AI 队友:monday.com 如何在 Amazon Bedrock 上运行生产级 AI 代理” AI 队友是运行于 Amazon Bedrock 的代理型 AI,而仅有少数工程组织能在像 monday.com 这样的规模上将其投入生产。十分之九的构建者每月使用 AI 编码工具,这一比例较半年前从约 50% 显著提升。每位工程师的 PR 吞吐量增长了超过一半。本文中的所有数据均源自 monday.com 自身的生产环境数据。本文将分享支撑这些数据的架构、使其在十年代码库中成功运行的改造措施,以及通过置信度评分合并策略缩小通往完全自主化差距的方法。 AI Teammates: how monday.com runs production AI agents on Amazon Bedrock aws.amazon.com
探索基于 Amazon Nova 的监督微调中的自蒸馏推理 在本文中,我们探讨了一种为缺乏推理轨迹的 SFT 定制数据集生成思维 token 的思路。我们首先分析推理抑制问题,随后提出自蒸馏推理(Self-Distilled Reasoning, SDR),并在三个基准测试中进行验证,最后提供实用建议。 Exploring self-distilled reasoning for supervised fine-tuning with Amazon Nova aws.amazon.com
AWS DeepRacer 设备现已支持自定义操作系统安装 使用原厂固件和软件时,开发者无法修改其 AWS DeepRacer 设备以使用最新操作系统。现在,开发者可通过新发布的引导加载程序(bootloader)升级或安装自定义操作系统(OS),从而延长这些硬件设备的使用寿命。在本篇博客中,我们将介绍该引导加载程序,讨论其使用方法,并提供使用它的社区发行版的链接。 Custom OS installation now available on AWS DeepRacer devices aws.amazon.com
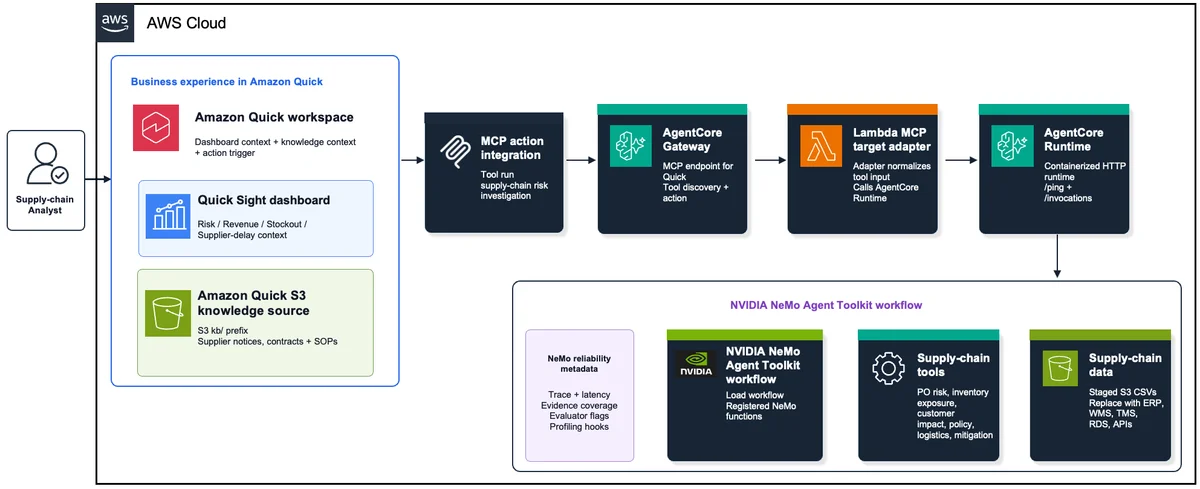
使用 Amazon Quick 和 NVIDIA NeMo Agent Toolkit 为您的业务构建专用智能体工作流 在本文中,我们展示了 Amazon Quick 如何作为业务用户访问专用代理工作流的入口。我们利用 NVIDIA NeMo Agent Toolkit 构建了一个供应链风险示例,帮助规划者从 Amazon Quick 仪表板和知识上下文过渡到引导式的缓解建议。 Build specialized agent workflows for your business with Amazon Quick and NVIDIA NeMo Agent Toolkit aws.amazon.com
Couchbase 如何为 Capella iQ 构建基于 Amazon Bedrock 的多模型 AI 架构 本文介绍了 Couchbase 如何采用 Amazon Bedrock 为 Capella iQ 提供动力,集成 Anthropic 的 Claude 系列模型,阐述了其多模型架构背后的设计决策,以及在生产环境中实现的运营效益。 How Couchbase built a multi-model AI architecture for Capella iQ with Amazon Bedrock aws.amazon.com
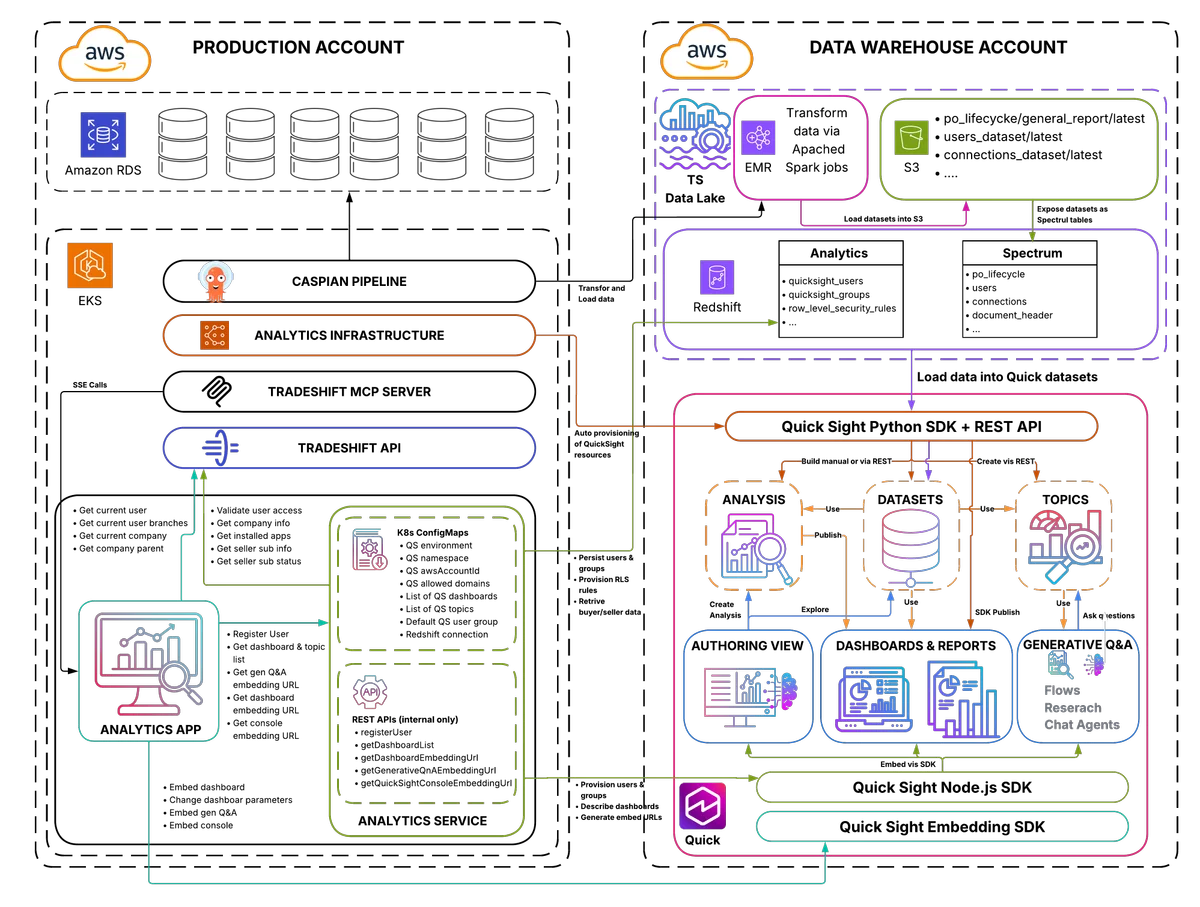
从传统商业智能演进至 Tradeshift 的代理式人工智能,借助 Amazon Quick 在本文中,我们介绍了 Tradeshift 如何利用具备智能体(agentic)AI 能力的 Amazon Quick 部署方案,替换其遗留的商业智能(BI)工具,实现了查询响应时间提升高达 30 倍、总体拥有成本降低 40%,并将嵌入式分析转化为能够产生收入的产品。 Evolving from legacy BI to agentic AI at Tradeshift with Amazon Quick aws.amazon.com
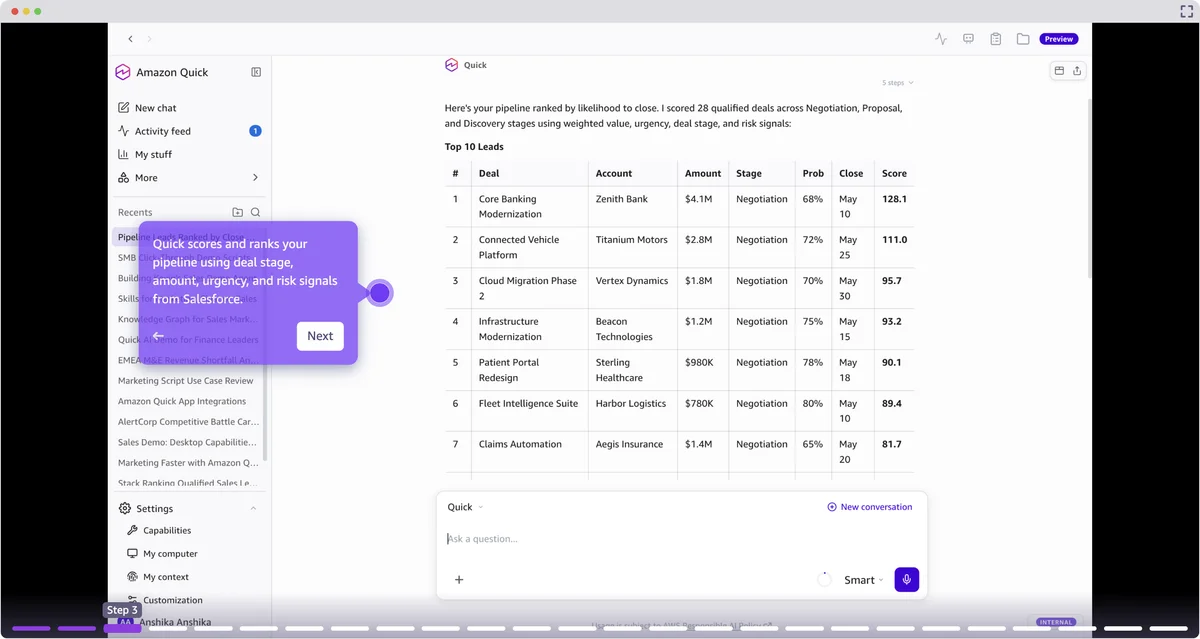
用 Amazon Quick 重塑您的销售组织:您全新的代理式 AI 队友 在本文中,我们将探讨 Quick 如何实现这一承诺。我们涵盖整个销售周期,从识别最高优先级的潜在客户、联系他们、推进交易直至成交,并在账户成熟过程中持续更新 CRM 系统,同时保护您最稀缺的资源:您的时间。 Transform your sales organization with Amazon Quick: your new agentic AI teammate aws.amazon.com
介绍 Amazon QuickSight 仪表板的移动布局 依赖仪表板进行日常决策的团队,往往不得不进行缩放操作才能与最初为大屏幕设计的控件进行交互。在晨会期间查看收入、会议间隙审查管道指标,或是在旅途中监控运营状况,当仪表板是为桌面屏幕构建时,这些操作都需要付出额外努力。Amazon 的移动端布局 [...] Introducing Mobile Layout for Amazon Quick dashboards aws.amazon.com
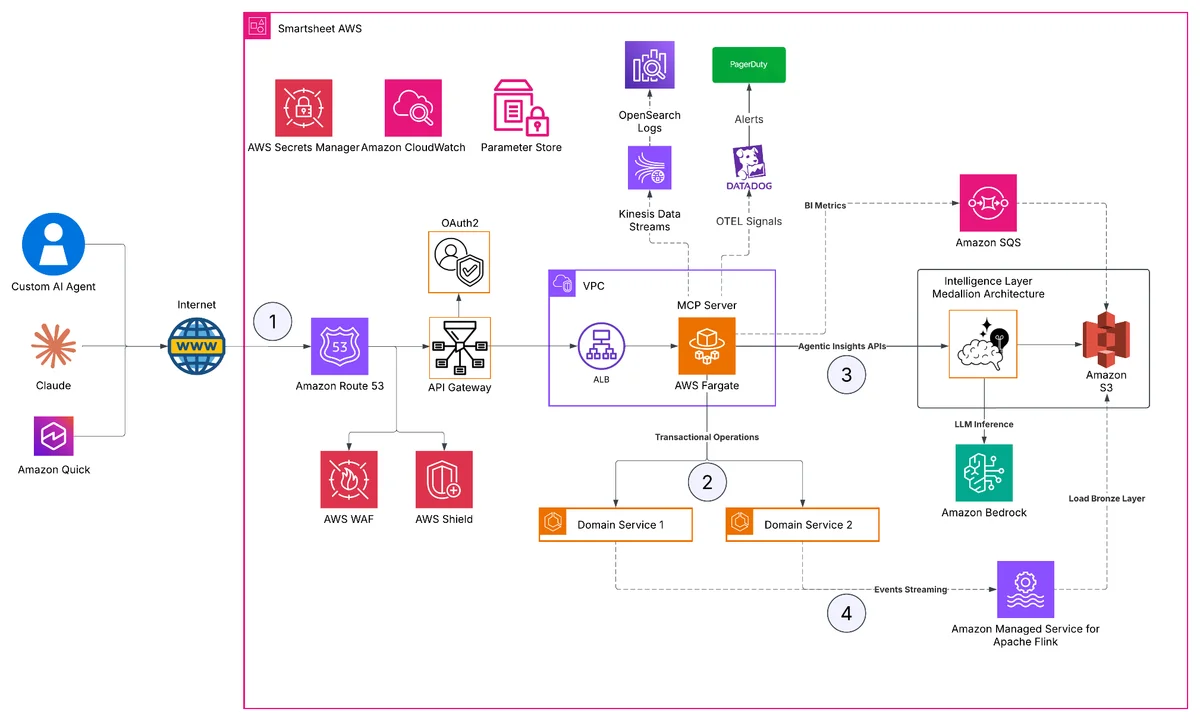
Smartsheet 如何在 AWS 上构建远程 MCP 服务器” 在本文中,我们将概述 Smartsheet 远程 MCP 架构的高层视图,重点介绍其背后的 AWS 基础设施。内容包括安全性、治理、扩展与部署,以及 Smartsheet 在 AWS 上构建的针对 AI 的特定优化。 How Smartsheet built a remote MCP server on AWS aws.amazon.com
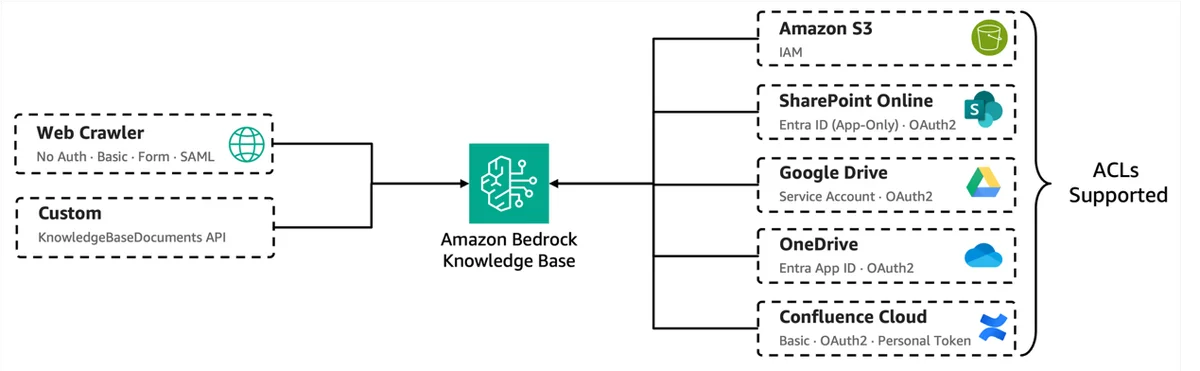
使用 Amazon Bedrock 托管知识库为智能体构建企业级搜索 在本文中,我们将介绍实现这一目标的三大支柱:简化设置、更智能的检索以及生产就绪性。同时,我们还将提供设置知识库并从其中检索数据的代码示例。 Build enterprise search for agents with Amazon Bedrock Managed Knowledge Base aws.amazon.com
在 Amazon Bedrock 上推出 Grok 本文介绍了 Grok 4.3 为何非常适合代理和企业级工作负载,如何通过 Amazon Bedrock 访问它,以及如何使用各团队最先采用的功能:基础聊天请求、可配置的推理努力、工具调用、结构化输出、图像输入以及有状态的多轮对话。 Introducing Grok on Amazon Bedrock aws.amazon.com
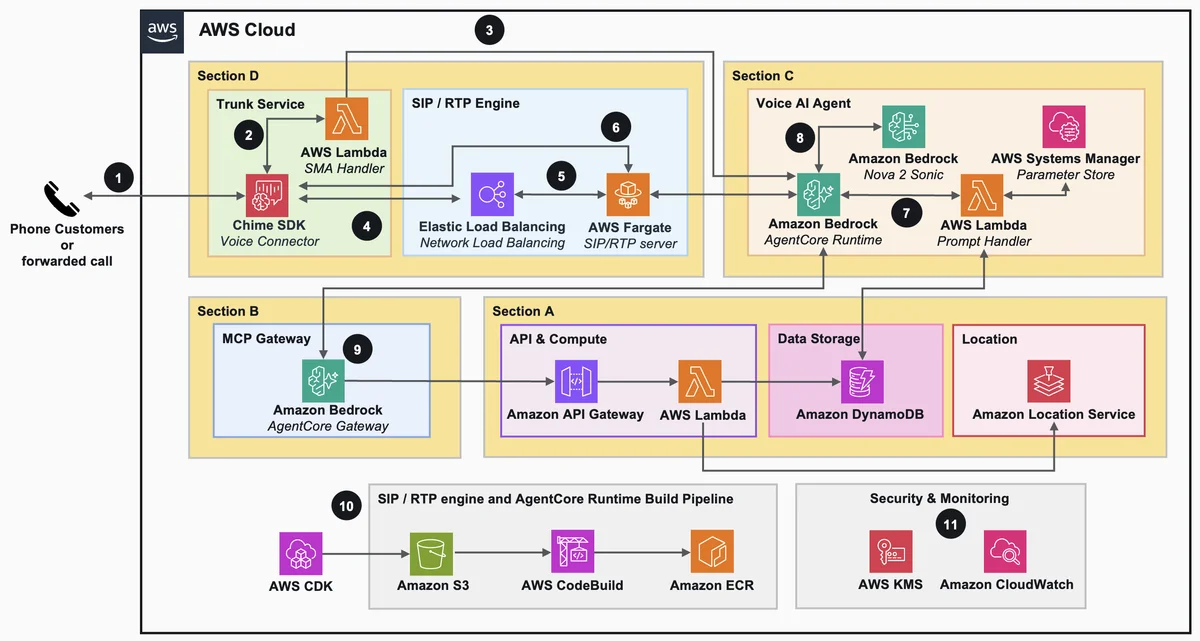
使用 Amazon Bedrock AgentCore 和 Amazon Nova 2 Sonic 构建餐厅电话 AI 主机 在本篇博客中,我们将展示如何构建一个语音点餐系统,该系统能够接听电话号码,并实现从问候到确认的完整点餐流程。该系统利用 Amazon Bedrock AgentCore 托管并运行智能体,采用 Amazon Nova 2 Sonic 进行实时语音处理,并通过模型上下文协议(MCP)连接至餐厅后端。本教程涵盖使用 AWS Cloud Development Kit(AWS CDK)部署全栈系统,并通过运行在 Amazon Elastic Container Service(Amazon ECS)和 AWS Fargate 上的会话初始化协议(SIP)网关将电话呼叫接入智能体。此外,系统在电话振铃期间即预热智能体会话,确保来电者不会听到沉默。 Building a restaurant telephony AI host with Amazon Bedrock AgentCore and Amazon Nova 2 Sonic aws.amazon.com
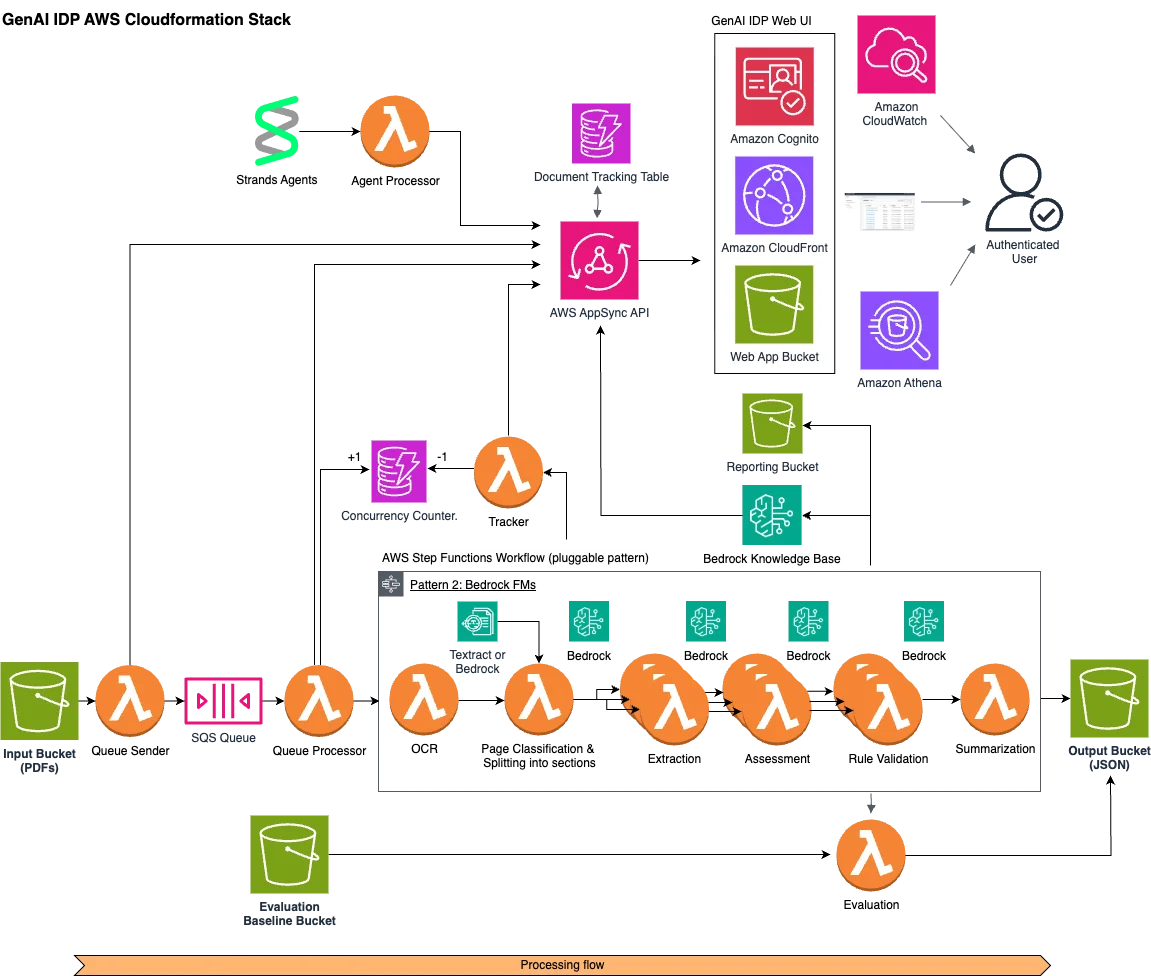
Built Technologies 在 AWS 上构建了一套人工智能驱动的文档智能解决方案,以赋能房地产金融领域的各类智能体。 Built 与 AWS 生成式人工智能创新中心(GenAIIC)、AWS 合作伙伴 AND Digital 以及 AWS 账户团队携手,打造了一套可扩展的 AI 驱动文档处理引擎,能够对复杂的房地产金融文档进行分类、拆分、提取、评估和推理。该引擎将原本需数天的工作流程缩短至数分钟,支持数百种文档类型,并为技术团队和行业专家提供了一个共建与优化文档处理器的共享环境。 Built Technologies builds an AI-powered document intelligence solution on AWS to power agents across real estate finance aws.amazon.com
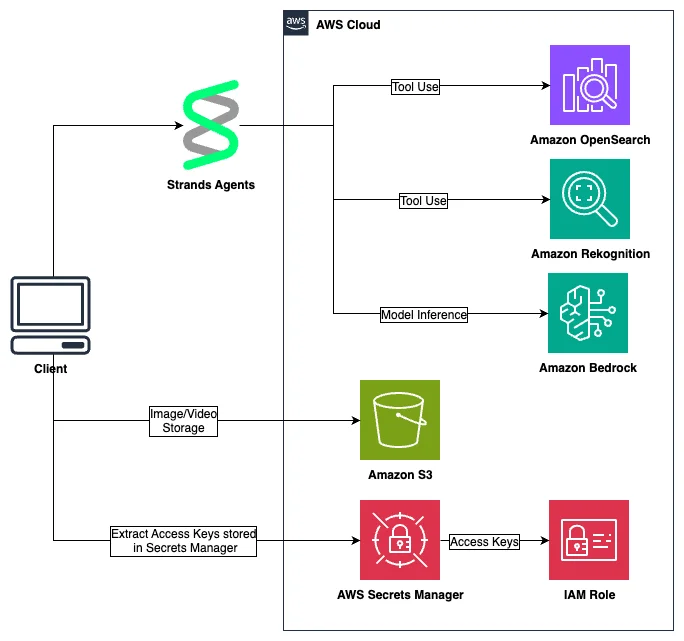
代理视觉:利用 Amazon Bedrock 和 MCP 服务器构建视觉智能 在本篇博客中,我们将带您了解计算机视觉 MCP 服务器,该服务器展示了这一方法,体现了 AI 系统如何通过单一标准化接口处理视觉信息并做出智能决策。这种融合将曾经复杂的集成挑战转化为简化的流程,使 AI 能力能够被更广泛的应用场景和开发者所利用。 Agentic vision: Building visual intelligence with Amazon Bedrock and MCP servers aws.amazon.com
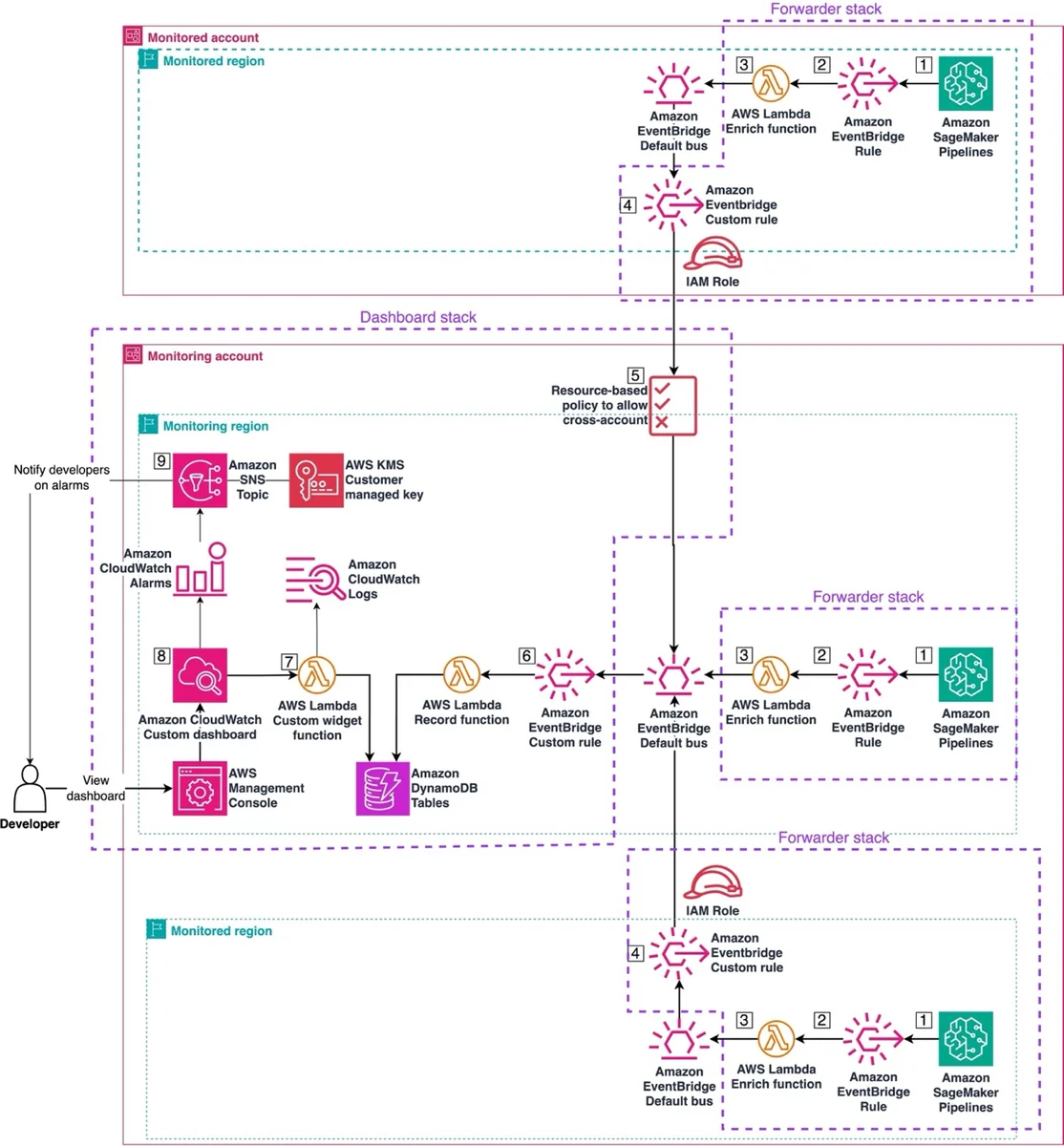
使用自定义 Amazon CloudWatch 仪表板跨账户监控 Amazon SageMaker Pipelines 在本文中,我们提出了一种解决方案,旨在利用 Amazon CloudWatch 自定义仪表板,集中监控跨 AWS 账户和区域的 SageMaker Pipelines。配套的 GitHub 仓库提供了所需基础设施的可定制 AWS Cloud Development Kit (AWS CDK) 示例。 Monitor Amazon SageMaker Pipelines cross-account with custom Amazon CloudWatch dashboards aws.amazon.com
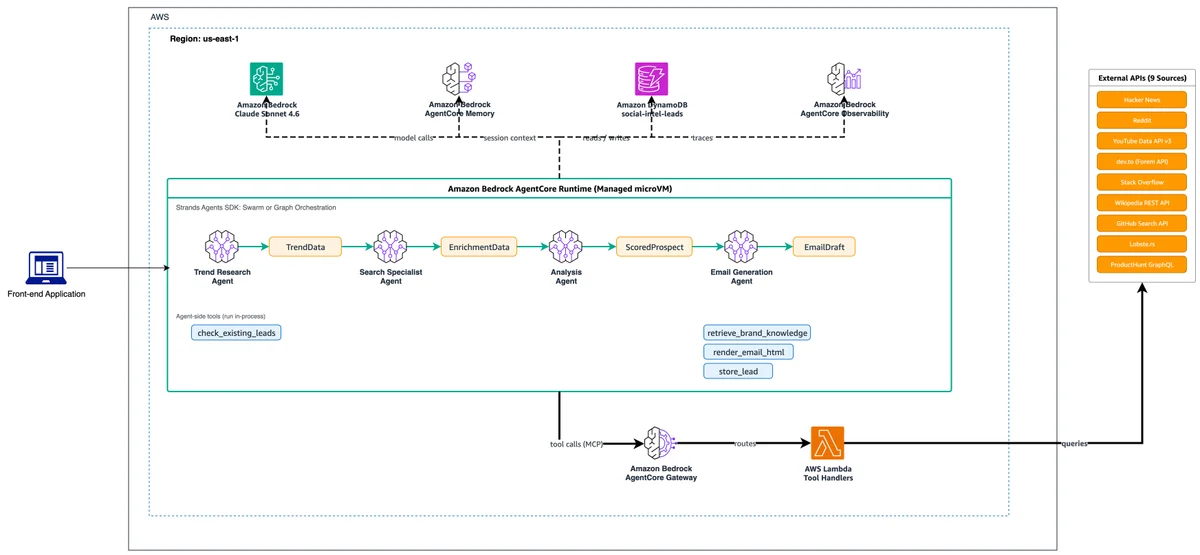
基于 Strands Agents 与 Amazon Bedrock 的多智能体社会智能 本文展示了 Thrad.ai 如何利用 Strands Agents 和 Amazon Bedrock AgentCore 部署一个多智能体系统,实现从潜在客户发现到个性化邮件生成的全流程自动化。文章对比了两种编排模式(Swarm 与 Graph),并通过延迟、成本和邮件质量三项指标进行了头对头基准测试。此外,您还将了解该系统如何基于加权标准、意图分类和时间衰减机制对潜在客户进行评分,以及用于生产部署的治理控制措施。 Multi-agent social intelligence with Strands Agents and Amazon Bedrock aws.amazon.com
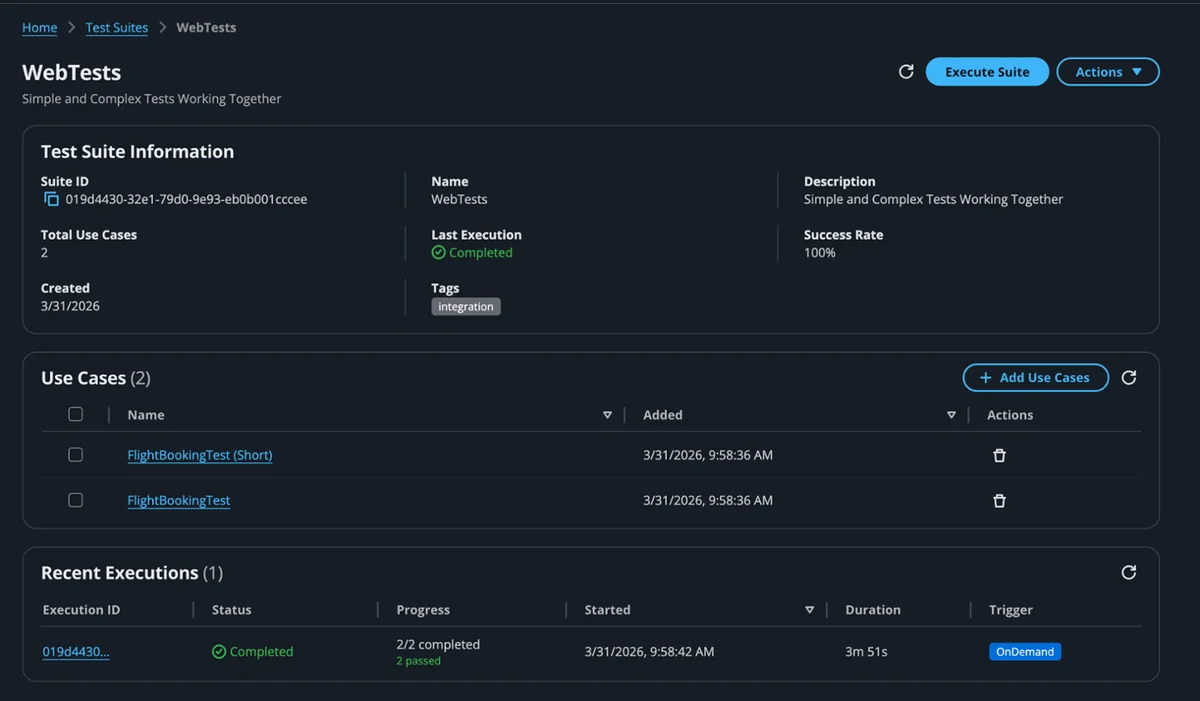
使用 Amazon Nova Act 实现代理式 QA 自动化以加速软件交付——第二部分 在本文中,我们在此基础上进一步展开,展示 QA Studio 如何通过测试套件组织并并行化执行以解决批量回归测试和流水线集成问题,以及通过命令行接口将智能体测试纳入自动化 CI/CD 流水线。 Accelerating software delivery with agentic QA automation using Amazon Nova Act – Part 2 aws.amazon.com
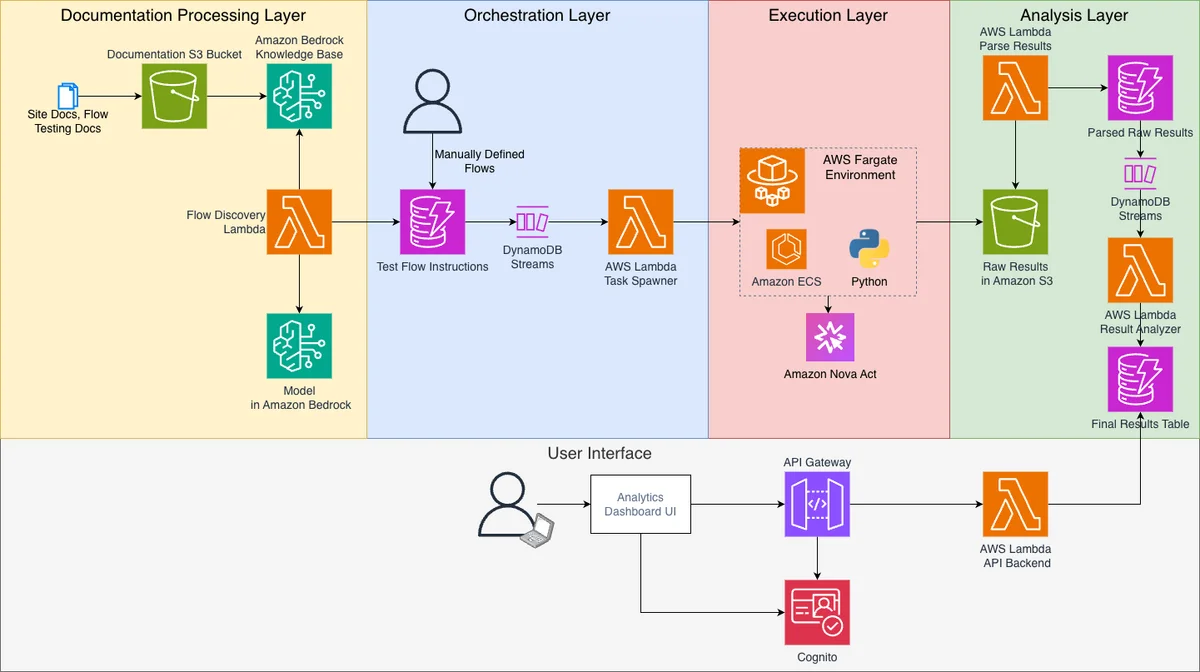
使用 Amazon Nova Act 扩展用户体验测试:用户流程分析的新方法 使用生成式 AI 可实现大规模并行执行全面的用户流程测试。本方案展示了如何构建一个云部署的 UX 测试平台,该平台能够从文档中自动生成测试场景,利用 Nova Act 的智能导航能力在大规模上执行用户流程,并通过自动化分析提供可操作的洞察。 Scaling UX testing with Amazon Nova Act: A new approach to user flow analysis aws.amazon.com
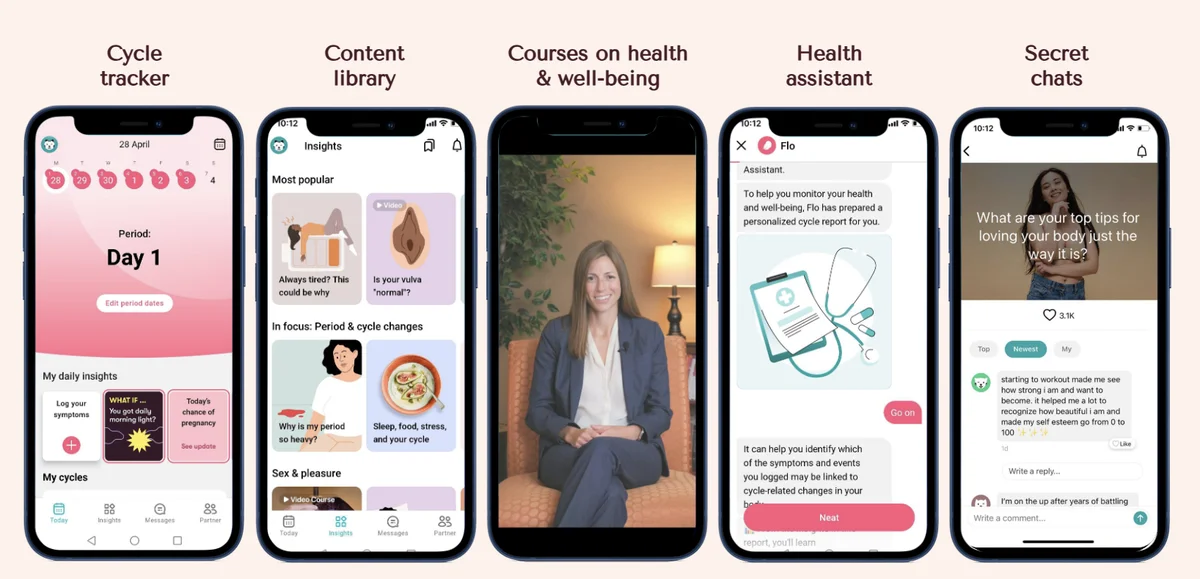
在 Flo Health 利用 Amazon Bedrock 扩展医疗内容审核——第二部分 在本文中,我们分享了 Flo Health 工程团队如何将来自 AWS 生成式人工智能创新中心的概念验证(PoC)转化为基于 Amazon Bedrock 构建的、面向生产环境的 AI 驱动医疗内容审查与生成系统。 Scaling medical content review at Flo Health with Amazon Bedrock – Part 2 aws.amazon.com
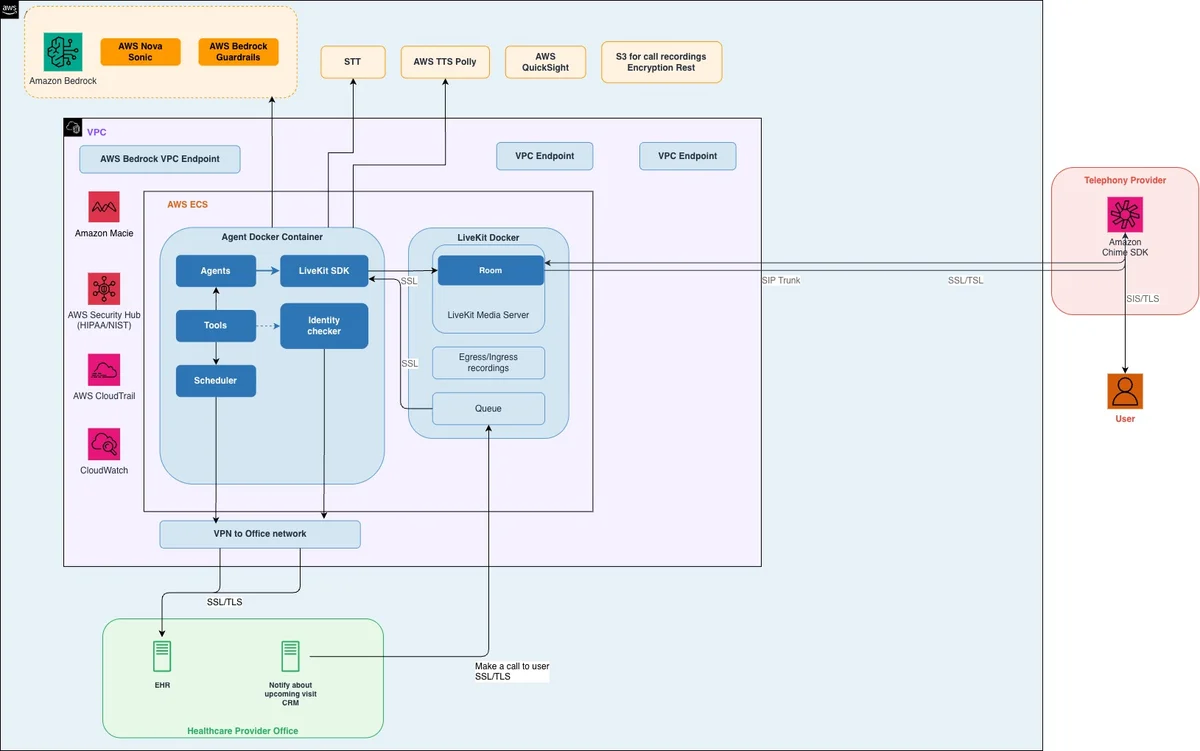
基于 AWS 构建的 ScienceSoft 符合 HIPAA 标准的 AI 语音调度器 在本文中,您将了解 AWS 服务合作伙伴 ScienceSoft 如何将 Amazon Nova 2 Sonic 与 Amazon Bedrock Guardrails 集成,以构建符合《健康保险流通与责任法案》(HIPAA)的 AI 语音调度系统。您将看到该解决方案如何解决医疗预约挑战,同时保持隐私、合规性和负责任的 AI 标准,以及如何将相同的架构应用于您的工作流程。 ScienceSoft’s HIPAA-compliant AI voice scheduler built on AWS aws.amazon.com
OpenAI GPT-5.6 Sol、Terra 和 Luna 现已在 Amazon Bedrock 上普遍可用。 如今,OpenAI 的 GPT-5.6 Sol、Terra 和 Luna 模型已在 Amazon Bedrock 上全面可用,将 OpenAI 迄今最强大的模型系列引入专为高性能、安全性和可靠性打造的 Amazon Bedrock 下一代推理引擎。 OpenAI GPT-5.6 Sol, Terra, and Luna are now generally available on Amazon Bedrock aws.amazon.com
当你的大脑运作方式不同时,人工智能并非奢侈品——而是可及性。 在本文中,我分享了人工智能如何作为神经多样性专业人士的辅助工具。该系统基于运行于您桌面的 Amazon Quick 构建,这是一款人工智能驱动的桌面与网络助手,能够每日弥补执行功能方面的差距。 When your brain works differently, AI isn’t a luxury—it’s accessibility aws.amazon.com
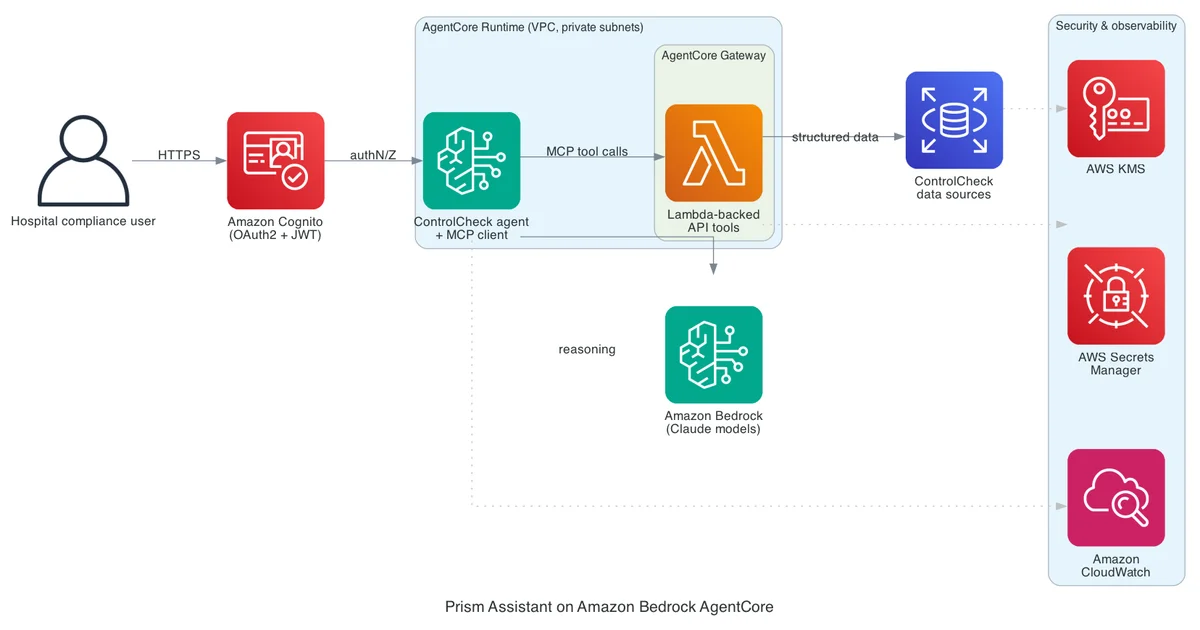
在 Bluesight 使用 Amazon Bedrock 构建代理型 AI 解决方案 在本文中,我们介绍了 Bluesight 如何通过两次 AWS 合作以及 Amazon Bedrock AgentCore,从单一产品 AI 原型演进为 Prism——一个涵盖六款医疗合规产品的统一代理式 AI 解决方案。Prism Assistant for ControlCheck 于 2026 年 5 月推出,目前已为 20 家医疗系统所采用。更为复杂的多产品代理式解决方案预计将于 2026 年下半年上线。 Building an agentic AI solution at Bluesight with Amazon Bedrock aws.amazon.com
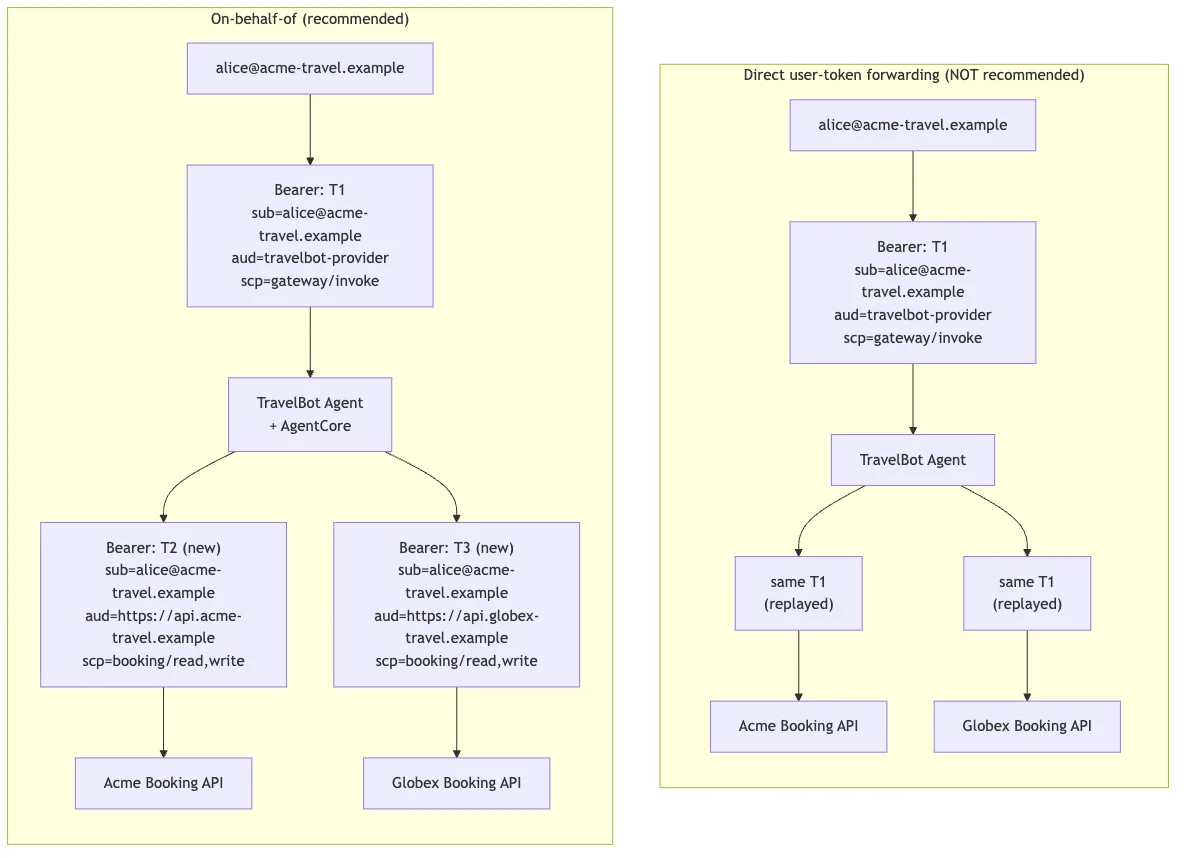
为多租户代理实现代表身份令牌交换,使用 Amazon Bedrock AgentCore 网关 使用 Amazon Bedrock AgentCore 构建多租户代理,并通过 Bedrock AgentCore Gateway 拦截器实施细粒度访问控制,为代理系统中的代表方(OBO)令牌交换奠定了概念基础。本文是实施指南,将完整演示针对 Okta 的多租户 OBO 配置,展示每一跳中的 JSON Web Token (JWT) 声明转换,并演示受众绑定如何产生可扩展至各租户的纵深防御。 Implement on-behalf-of token exchange for multi-tenant agents with Amazon Bedrock AgentCore Gateway aws.amazon.com
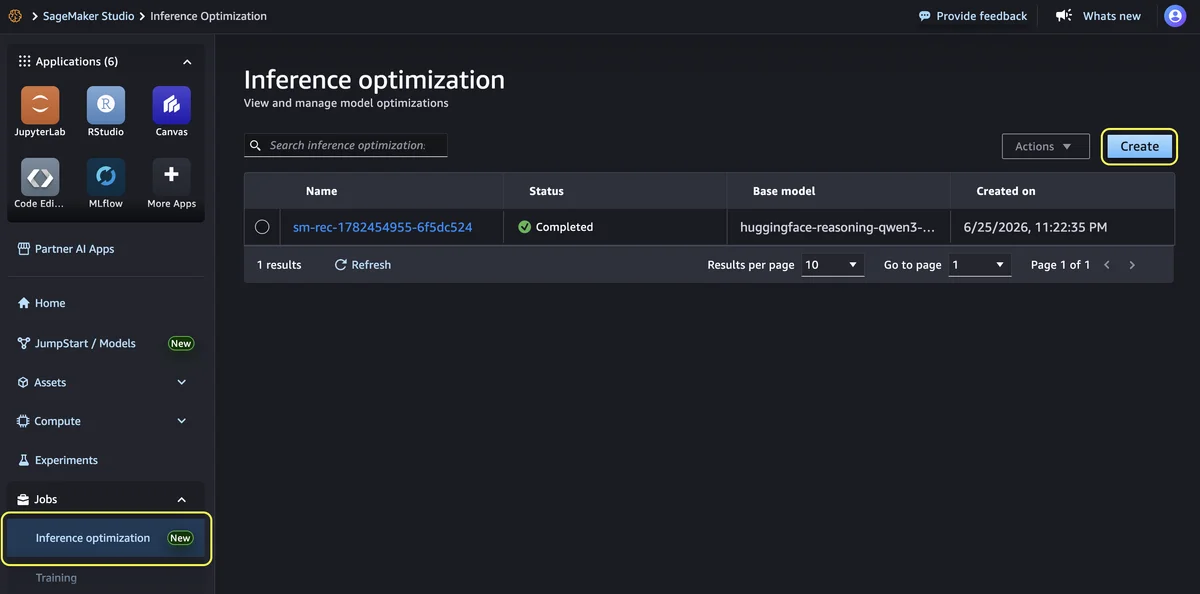
在 Amazon SageMaker AI 中推出用于生成式 AI 推理推荐的界面 在本文中,我们介绍了 Amazon SageMaker AI Studio 中用于优化生成式 AI 推理推荐的界面,这是一种低代码/无代码(LCNC)体验。该 API 已提供对推荐的程序化访问,但假设您了解需要设置哪些参数以及如何解读原始基准测试结果。该界面消除了这一假设,通过预设用例配置文件、结果可视化对比以及一键部署功能,引导用户完成操作,使不具备深厚基础设施专业知识的团队也能自行获得经过验证的配置。 Launching UI for generative AI inference recommendations in Amazon SageMaker AI aws.amazon.com
使用 Amazon SageMaker AI 无服务器模型定制功能微调 NVIDIA Nemotron 3 模型 在本文中,我们将探讨 Nemotron 3 架构的独特之处,介绍可用的微调技术,并逐步演示如何使用 SageMaker Studio 启动无服务器定制。 Fine-tune NVIDIA Nemotron 3 models with Amazon SageMaker AI serverless model customization aws.amazon.com
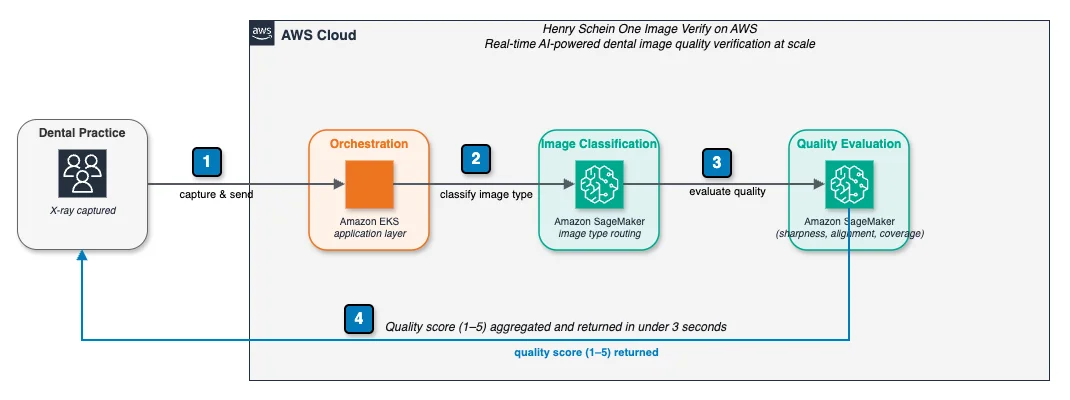
亨利·谢因 One 利用 Amazon SageMaker AI 实现牙科图像的实时验证 本案例介绍了 Henry Schein One 如何通过构建 Image Verify 来弥合这一差距。Image Verify 是一个基于 Amazon SageMaker AI 打造的 AI 驱动影像质量验证系统,能够在拍摄点实时对牙科 X 光片质量进行评估,并覆盖数千个地点。该系统从概念到在超过 10,000 个活跃地点上线仅用了数月时间,目前已处理超过 1,100 万张 X 光片,且以每周 150 万张的速度持续增长。Henry Schein One 正朝着全球四个区域共 40,000 个地点的规模扩展。 Real-time dental image verification with Amazon SageMaker AI at Henry Schein One aws.amazon.com
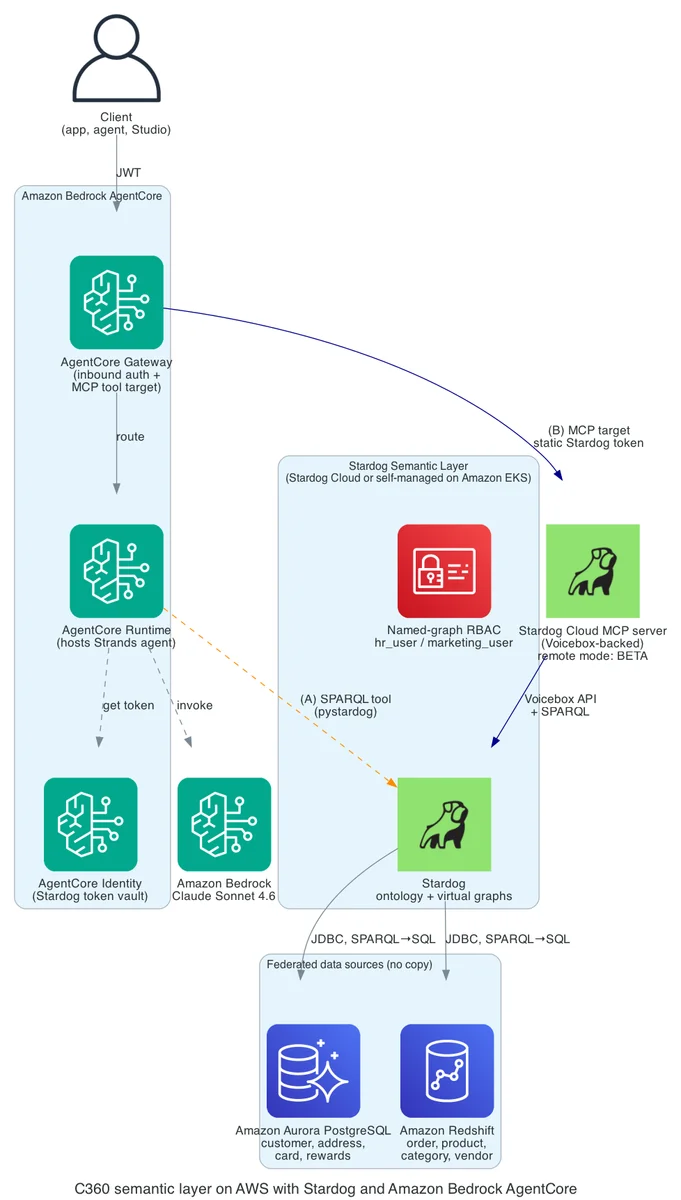
在 AWS 上利用 Stardog 和 Amazon Bedrock AgentCore 构建面向代理型 AI 的语义层 在本文中,我们将展示如何在 AWS 上构建语义层,利用 Stardog 的语义 AI 应用程序基于 Amazon Aurora 和 Amazon Redshift 实现,并演示如何在 Amazon Bedrock AgentCore 上运行 Strands Agents 代理,以查询该语义层,从而在不进行提取、转换和加载(ETL)的情况下,跨两个数据源回答客户 360 问题。相同的 Stardog 部署可服务于 AWS 计算服务(Amazon Elastic Kubernetes Service (Amazon EKS)、Amazon Elastic Container Service (Amazon ECS) 和 AWS Lambda)。本文选用 AgentCore,因为它将入站认证、托管和工具凭据整合为单一托管服务。 Build a semantic layer for agentic AI on AWS with Stardog and Amazon Bedrock AgentCore aws.amazon.com
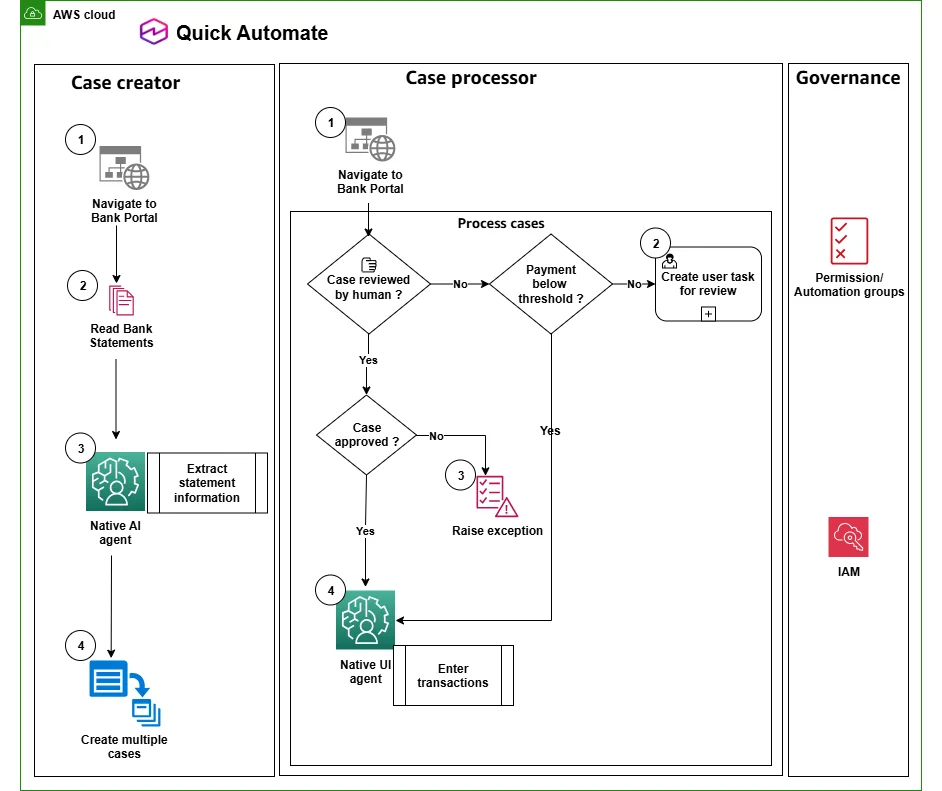
使用 Amazon Quick Automate 的原生案件管理扩展代理工作流 在本文中,我们将展示如何在 Quick Automate 中将案件管理与代理自动化能力相结合。我们介绍案件管理,并探讨代理工作流中案件的生命周期,涵盖从案件创建、处理到解决的全过程。我们将介绍如何创建和管理单个或多个案件,自动跟踪和更新状态,处理异常,并在工作流中纳入人机协同(HITL)步骤。此外,我们还将展示支持动态扩展的案件创建者 - 处理者模式。最后,我们将通过一个真实用例,演示如何为企业流程构建案件管理,包括人机协同和案件跟踪。 Scaling agentic workflows with native case management in Amazon Quick Automate aws.amazon.com
在 Amazon SageMaker AI 上使用 Unsloth 部署量化模型 在本文中,您将学习四种部署模式,用于将已使用 Unsloth 进行量化的模型部署到 AWS 基础设施上。这些模式利用 Amazon Elastic Compute Cloud(Amazon EC2)实现直接实例访问,利用 Amazon SageMaker AI 推理端点进行托管式服务,并在推理需求需适配现有容器框架时,采用 Amazon Elastic Kubernetes Service(Amazon EKS)或 Amazon Elastic Container Service(Amazon ECS)。此外,您还将了解生产环境部署的运营实践。 Deploying quantized models on Amazon SageMaker AI with Unsloth aws.amazon.com
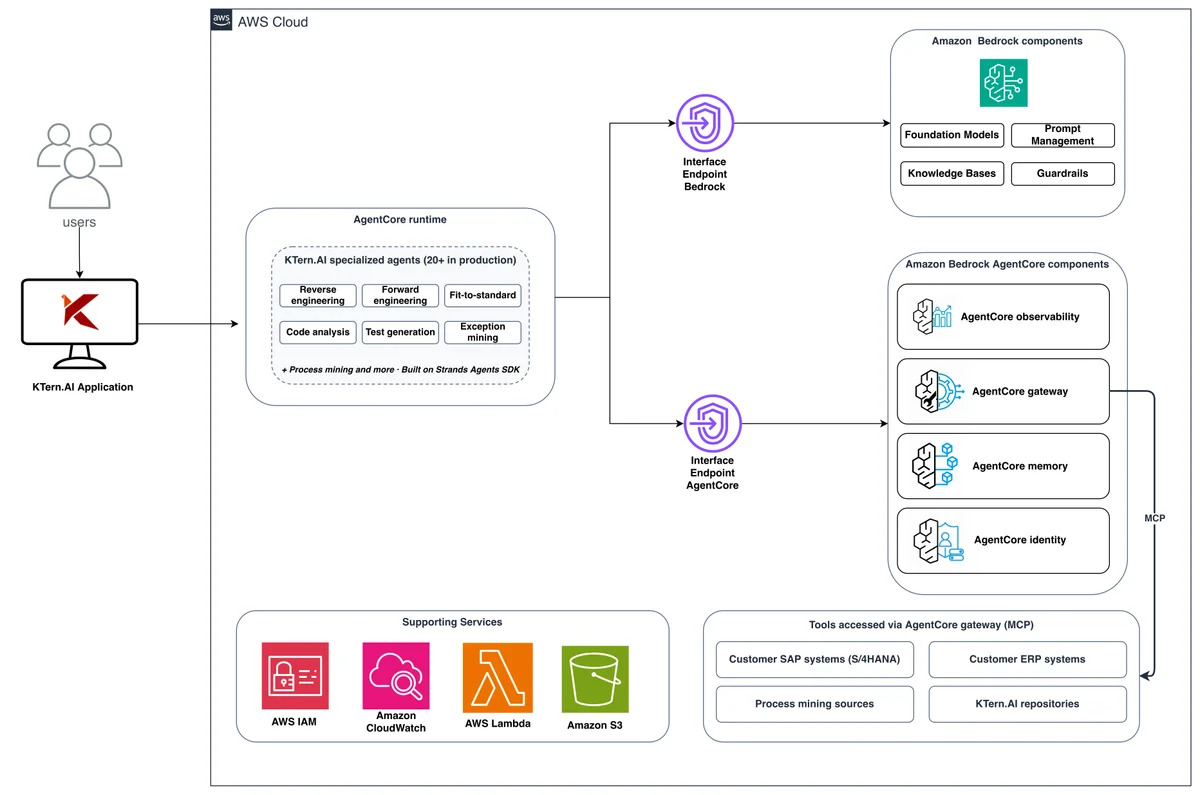
KTern.AI 如何在 Amazon Bedrock AgentCore 上构建面向 SAP 的智能体 AI 从传统的软件即服务(SaaS)平台演进为下一代代理式人工智能平台,意味着需要在长期运行的企业项目中编排多个专用代理。每个代理均具备持久化上下文、安全的工具访问能力以及生产级可靠性。我们基于 Amazon Bedrock AgentCore 和 Strands Agents SDK 构建了该系统。本文将介绍我们的架构设计、所构建的代理类型,以及为客户带来的成果。 How KTern.AI built agentic AI for SAP on Amazon Bedrock AgentCore aws.amazon.com
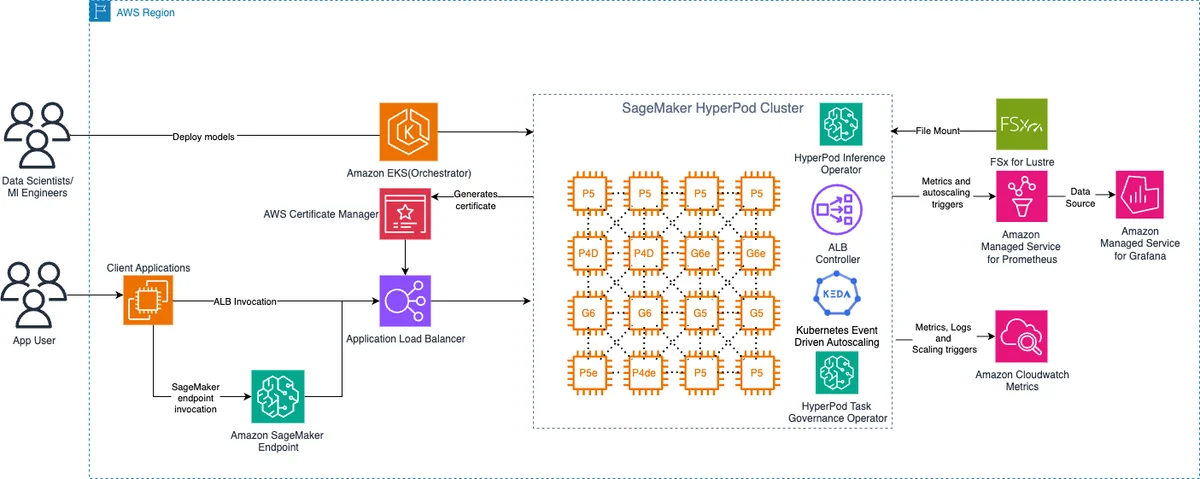
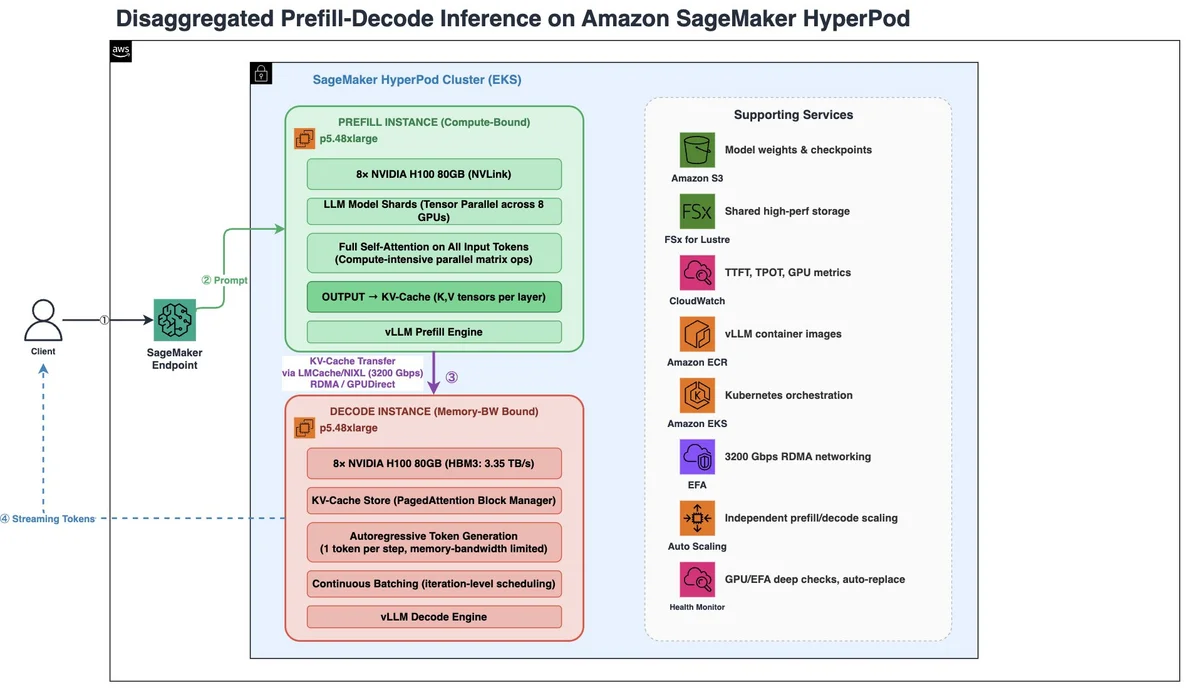
SageMaker HyperPod 上 LLM 推理的解耦预填充与解码 在本文中,我们展示了如何使用 HyperPod 推理算子,在 Amazon SageMaker HyperPod 上实现基于 vLLM 的 DPD。 Disaggregated prefill and decode for LLM inference on SageMaker HyperPod aws.amazon.com
MCP 工具设计:实用方法与权衡 在本文中,我们将展示 MCP 工具设计中的常见误区,并介绍如何通过实用的上下文工程方法加以解决。 MCP tool design: Practical approaches and tradeoffs aws.amazon.com
通过数据捕获、Hugging Face、NVMe 和 Route 53 集成增强 Amazon SageMaker HyperPod 的企业级推理 在本文中,我们将介绍 SageMaker HyperPod 推理现已提供的五项功能:用于审计和模型改进的多级数据捕获、直接从 Hugging Face Hub 部署、本地 NVMe 模型加载以实现更快的冷启动、用于自定义域名的自动化 Route 53 DNS,以及通过自定义服务账号实现的 Pod 级别 IAM。 Enhancing enterprise inference on Amazon SageMaker HyperPod with data capture, Hugging Face, NVMe, and Route 53 integration aws.amazon.com
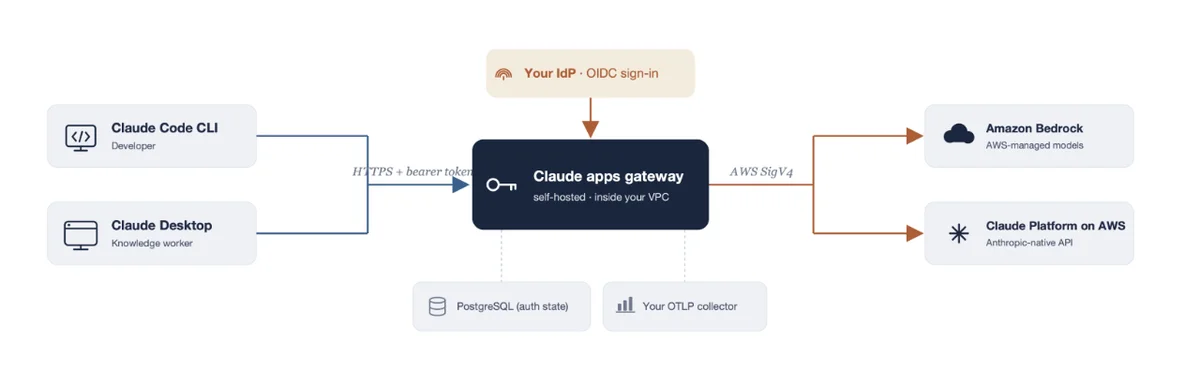
介绍用于 AWS 的 Claude 应用网关 今天,我们宣布推出面向 AWS 的 Claude 应用网关,这是一个自托管的控制平面,使组织能够对 Claude Code 和 Claude Desktop 的访问、成本及策略实现统一管控。在本篇博客中,我们将展示如何在 AWS 上结合 Amazon Bedrock 和 Claude Platform 部署并运行 Claude 应用网关。 Introducing Claude apps gateway for AWS aws.amazon.com
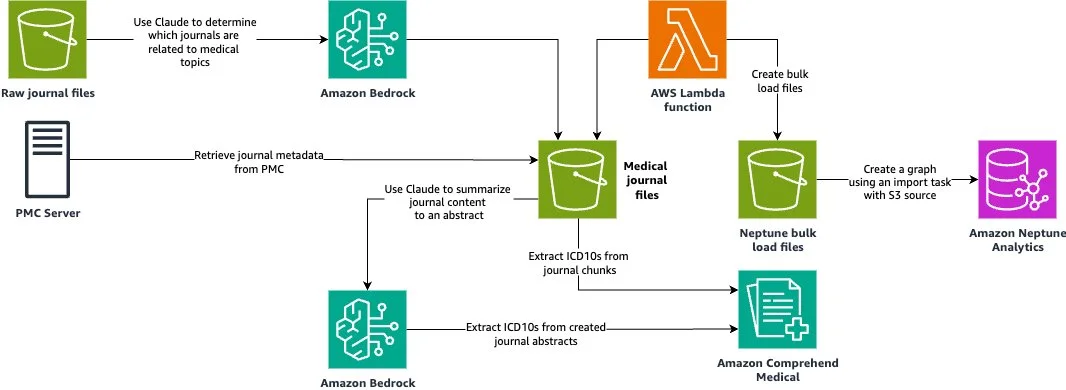
赋能科学发现:BYOKG 与 GraphRAG 助力智能药物研发 在本文中,我们探讨图检索增强生成(GraphRAG)如何通过结合图数据库与生成式人工智能,正在变革科学研究。借助这一方法,您可以在不牺牲科学严谨性的前提下加速发现进程。 Powering scientific discovery: BYOKG and GraphRAG for intelligent pharmaceutical research aws.amazon.com
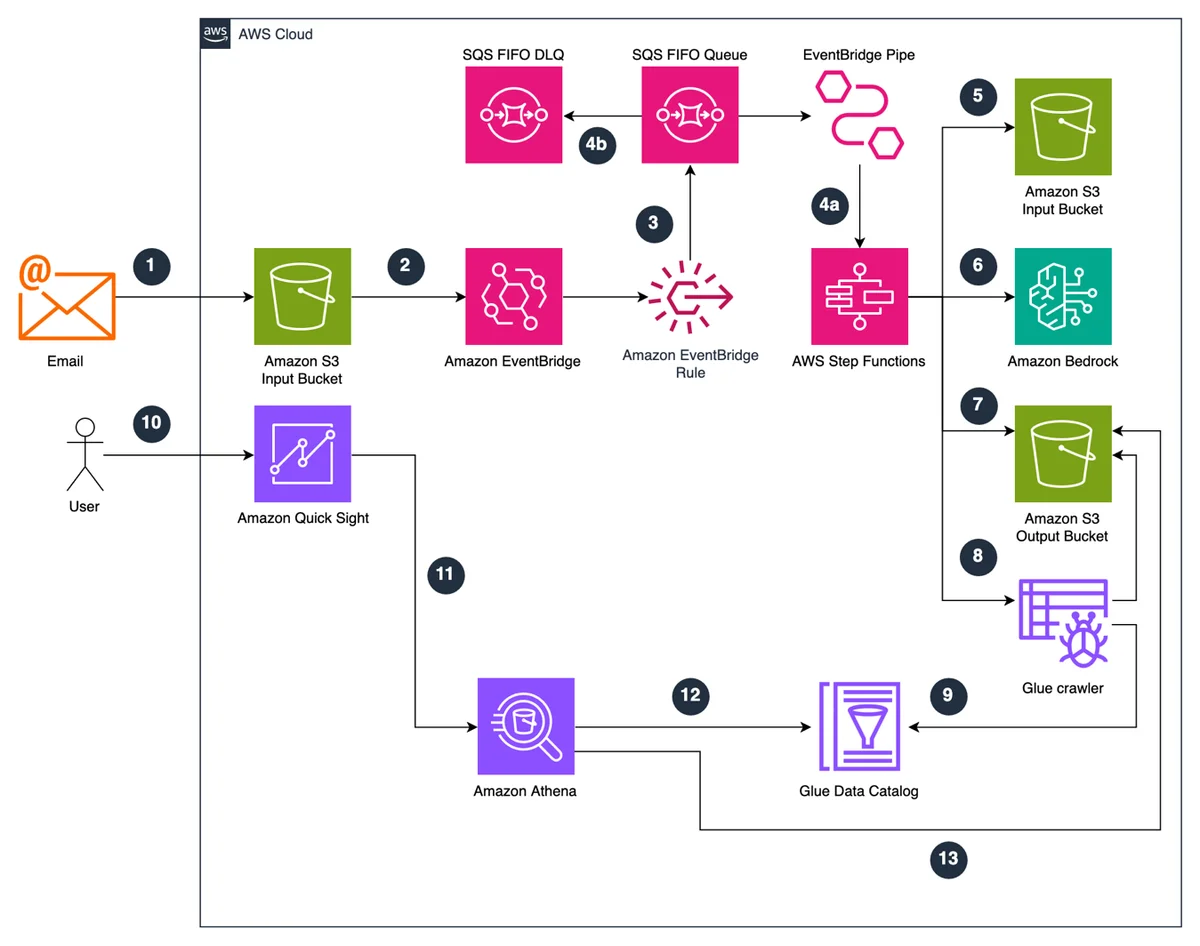
使用 Amazon Bedrock 自动对邮箱进行排序和优先级划分 在本文中,我们展示了公共部门组织如何利用由 Amazon Bedrock 驱动的生成式 AI 解决方案实现电子邮件管理的自动化。 Automatically sort and prioritize your mailboxes by using Amazon Bedrock aws.amazon.com
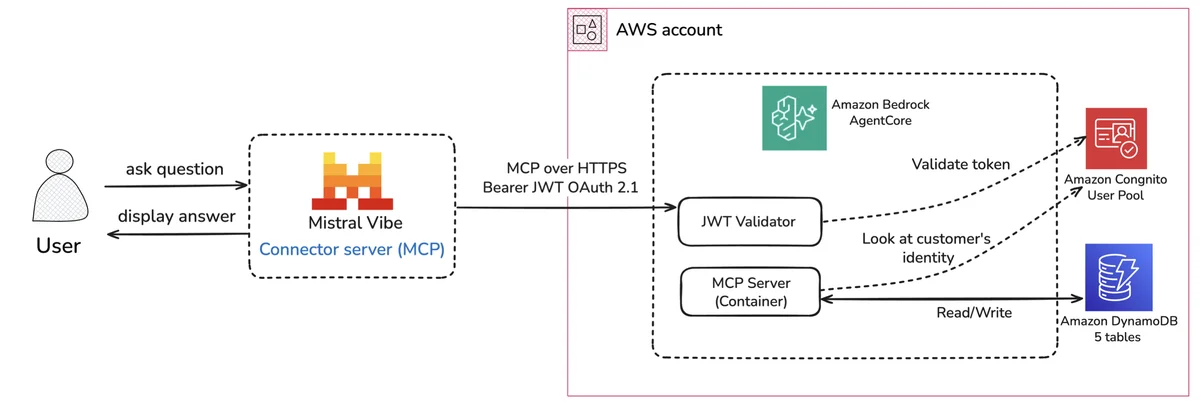
使用 Amazon Bedrock AgentCore 和 Mistral AI Studio 构建并连接生产就绪的电商 MCP 服务器 在本篇博客中,您将从头到尾构建并连接该服务器端。您将实现 MCP 工具,配置两层 JSON Web Token(JWT)身份验证,使用 AWS Cloud Development Kit(AWS CDK)进行部署,并将结果连接到 Mistral AI 的 Vibe。本文还涵盖先决条件、解决方案架构、MCP 服务器和 Vibe 连接器的最佳实践,以及资源清理。所构建的电商服务器支持产品搜索、订单提交、评论提交和退货处理,使用 Amazon DynamoDB 进行数据存储,使用 Amazon Cognito 进行身份管理。 Building and connecting a production-ready ecommerce MCP server using Amazon Bedrock AgentCore and Mistral AI Studio aws.amazon.com
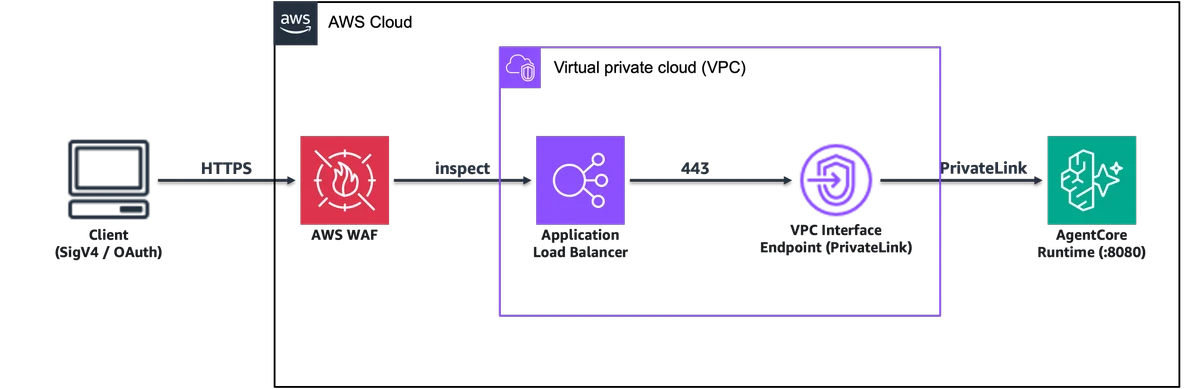
使用 AWS WAF 保护 Amazon Bedrock AgentCore Runtime 本文展示了两种用于解决该问题的架构模式。两者均采用面向互联网的 ALB,并配置 AWS WAF,将流量通过 VPC 接口端点路由至 AgentCore Runtime。模式 1 在 ALB 与 VPC 端点之间部署 AWS Lambda 代理,从而实现对请求转换的完全控制。模式 2 则直接从 ALB 访问 VPC 端点的 ENI IP 地址,彻底消除了 Lambda 跳转。此外,您还将学习如何通过资源策略关闭直接访问的后门,确保流量仅通过 AWS WAF 流转。这两种模式均已通过端到端测试,支持 SigV4 和 OAuth(Amazon Cognito JWT)身份验证。 Securing Amazon Bedrock AgentCore Runtime with AWS WAF aws.amazon.com
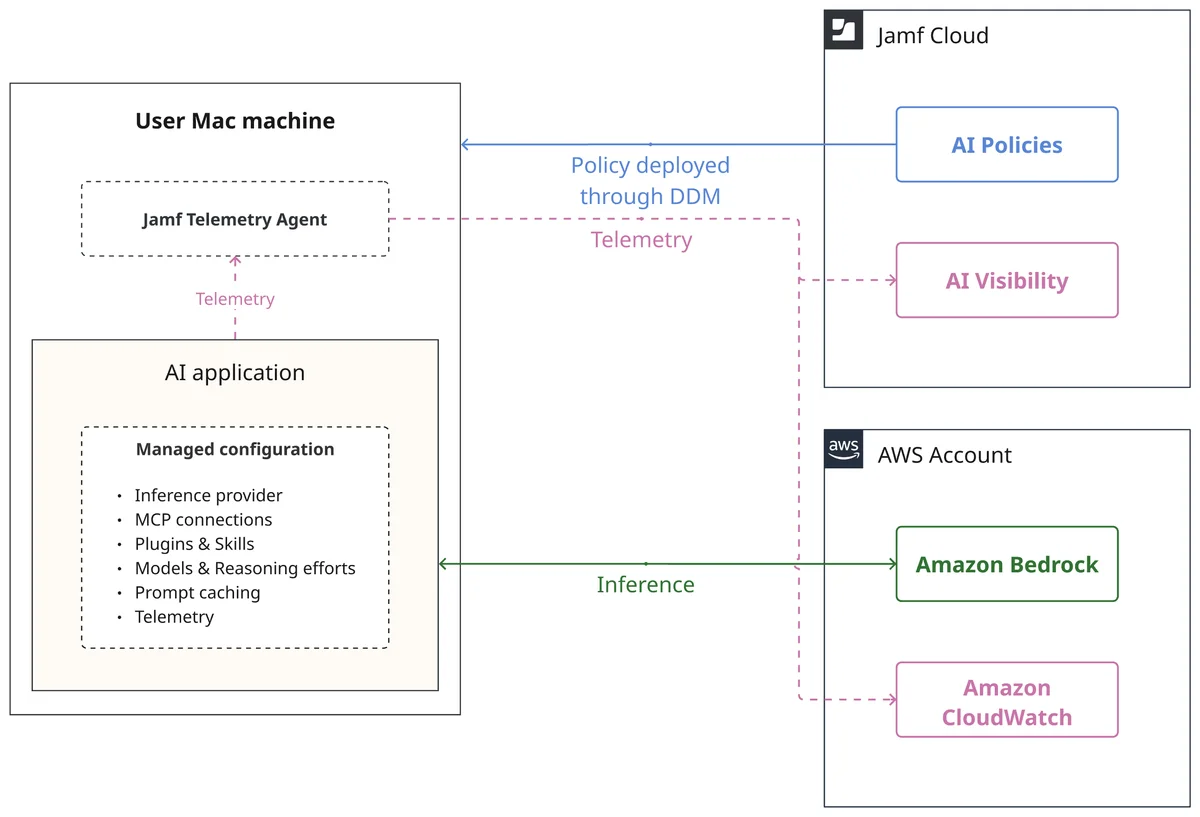
在 Mac 上通过 Jamf 的 AI 治理与 Amazon Bedrock 管理 AI 应用 在本文中,我们将展示如何使用 Jamf 的 AI 治理与 Amazon Bedrock 相结合,为 Mac 机队中的 AI 应用程序配置、部署并验证托管设置。 Manage AI applications on Mac with Jamf’s AI Governance and Amazon Bedrock aws.amazon.com
通过业务上下文丰富您的数据集:从传统主题迁移到 Amazon Quick 中的语义数据集 在本文中,我们将介绍什么是数据集增强,它与传统主题有何不同,并提供三个迁移场景及分步指导,帮助您自信地将业务上下文迁移至数据集层。 Enrich your datasets with business context: Migrating from legacy Topics to semantic datasets in Amazon Quick aws.amazon.com