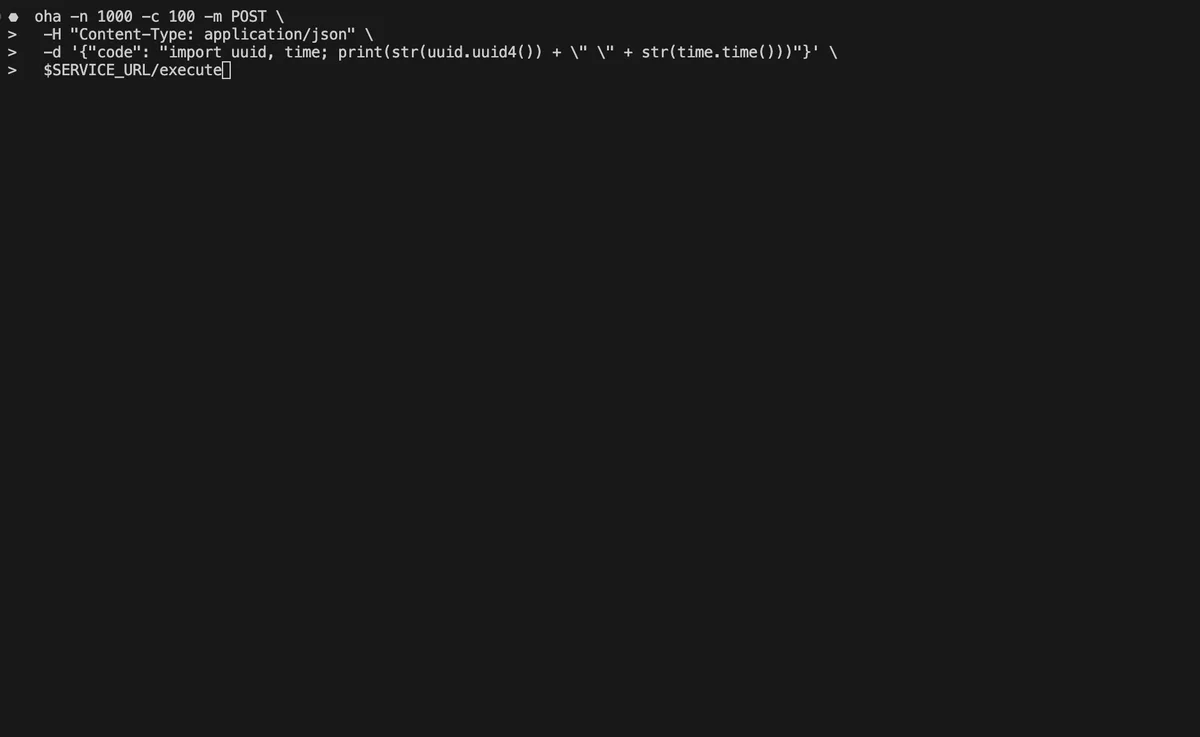
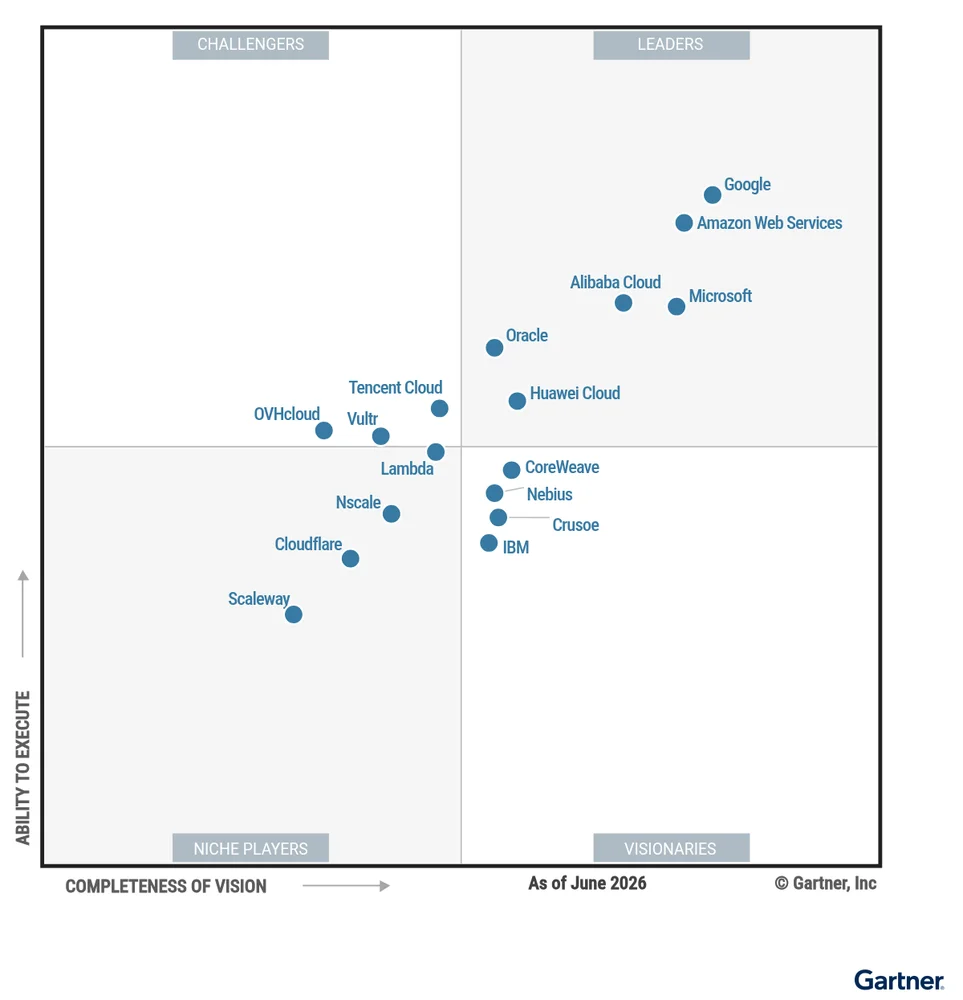
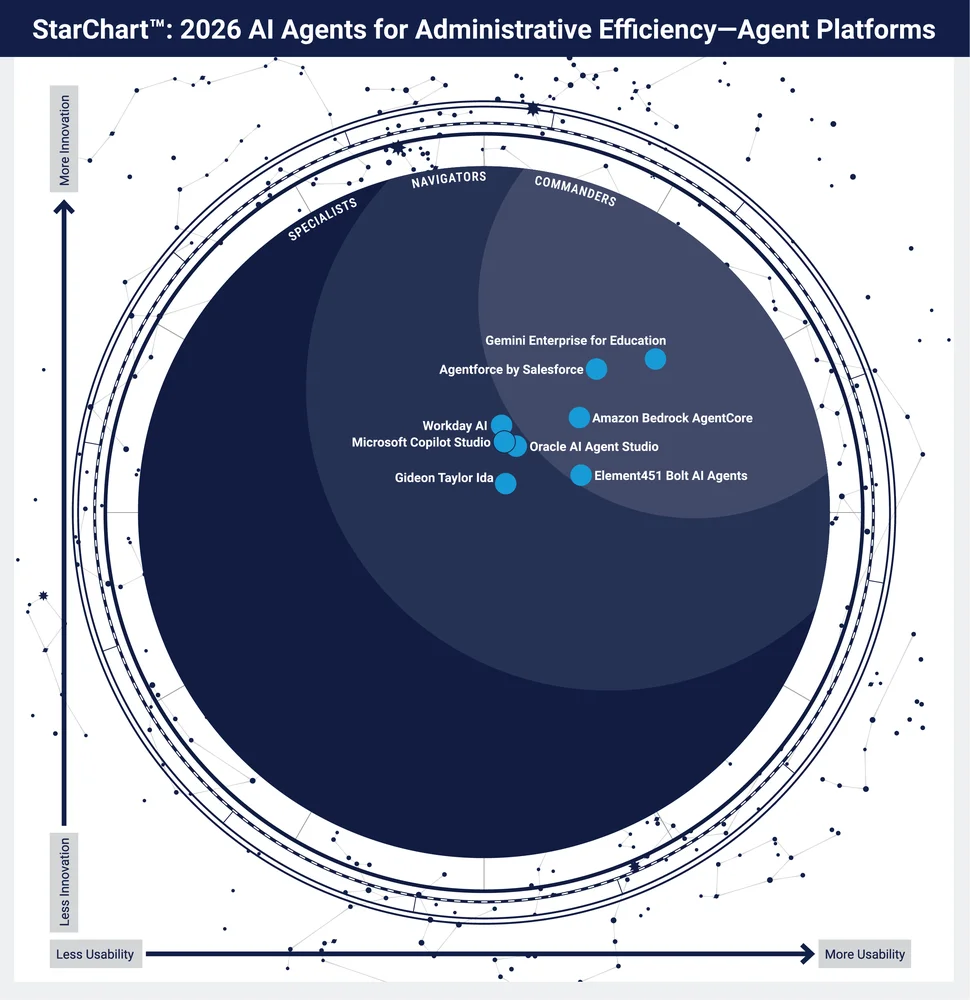
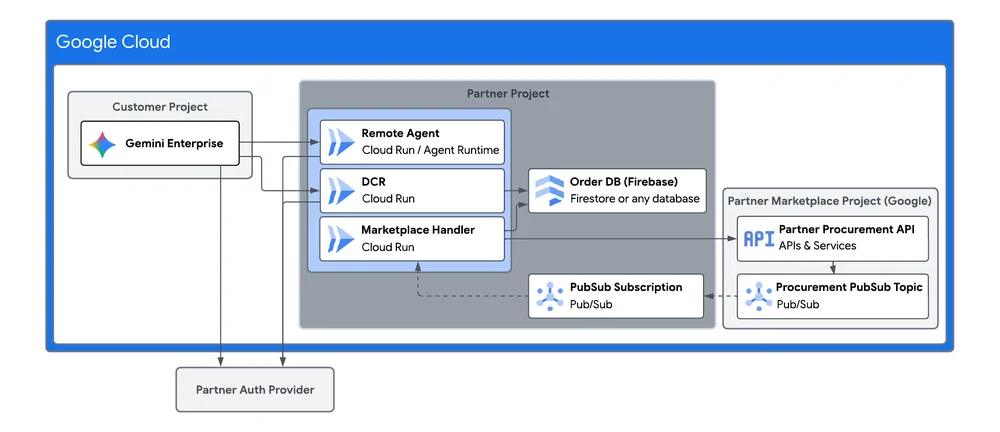
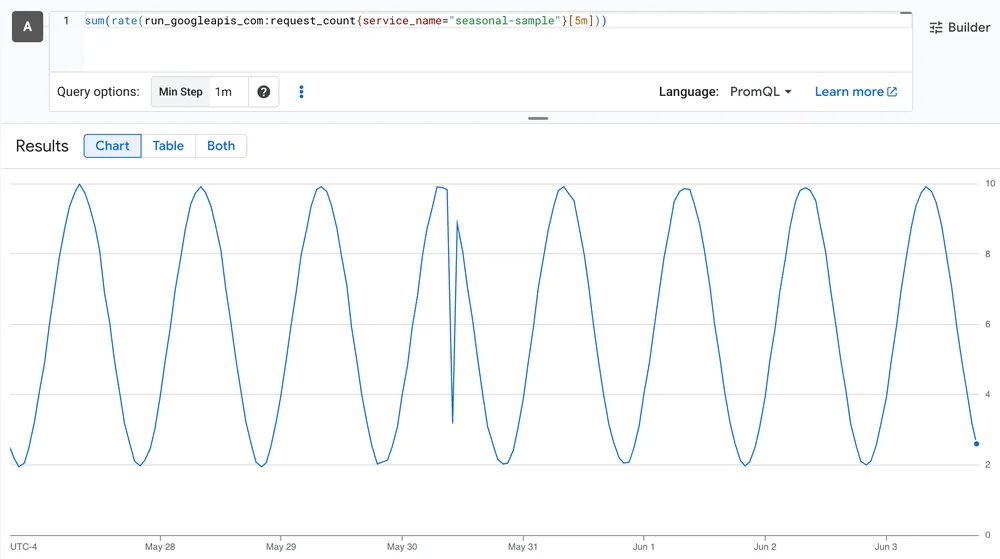
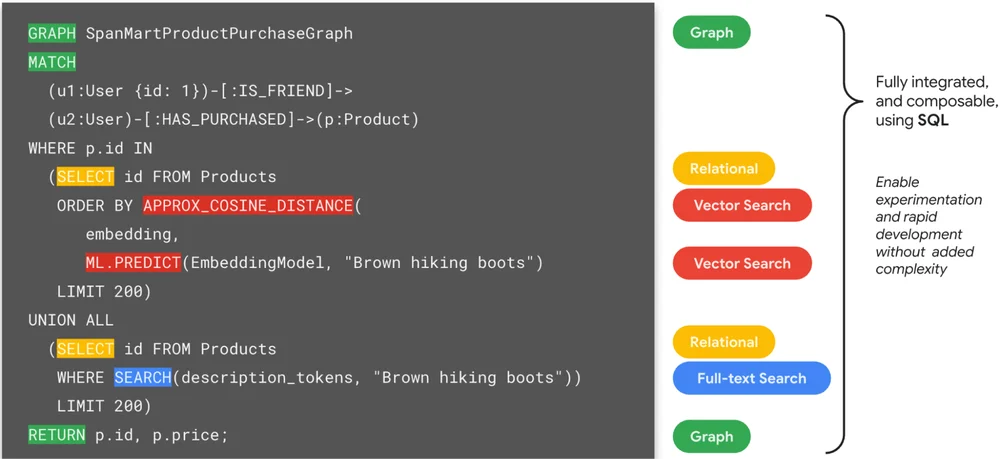
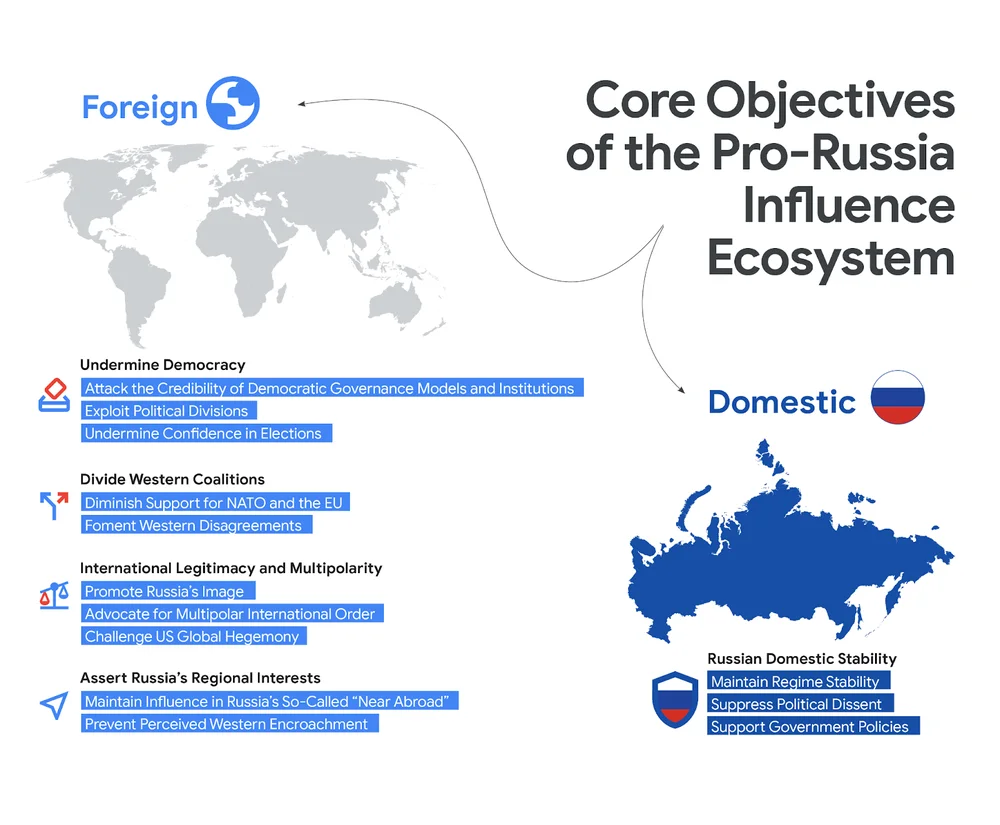
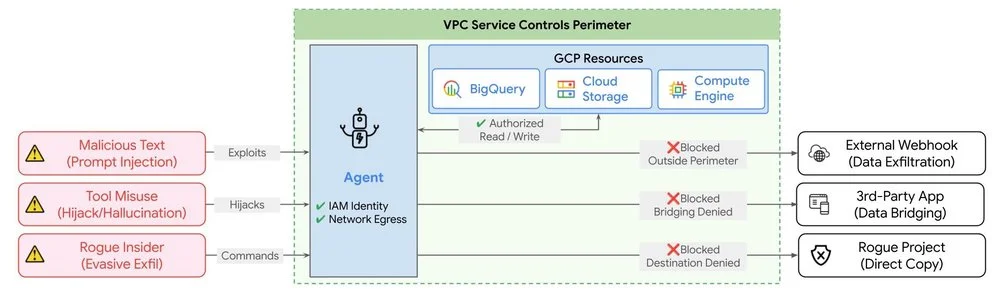
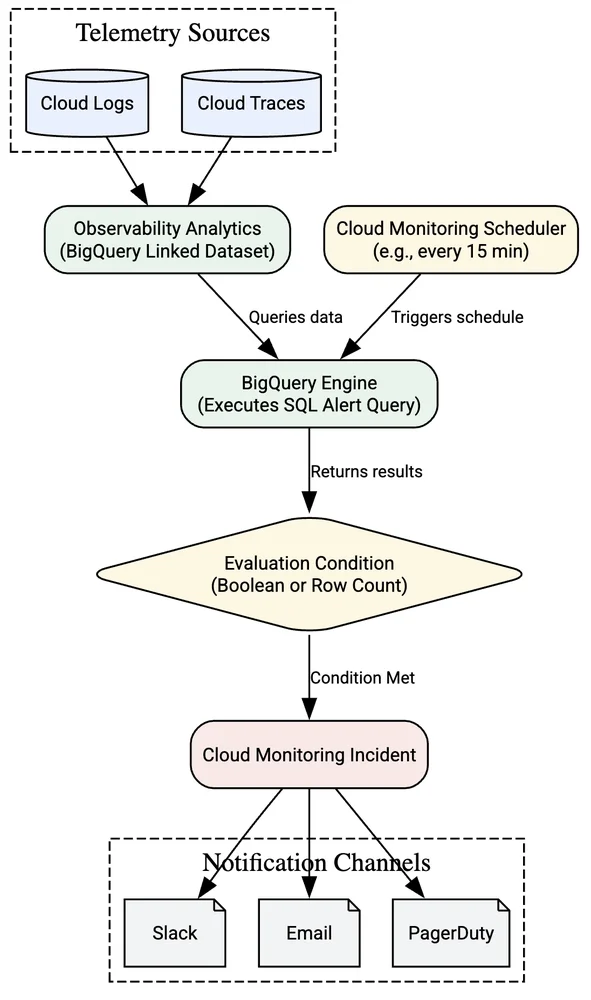
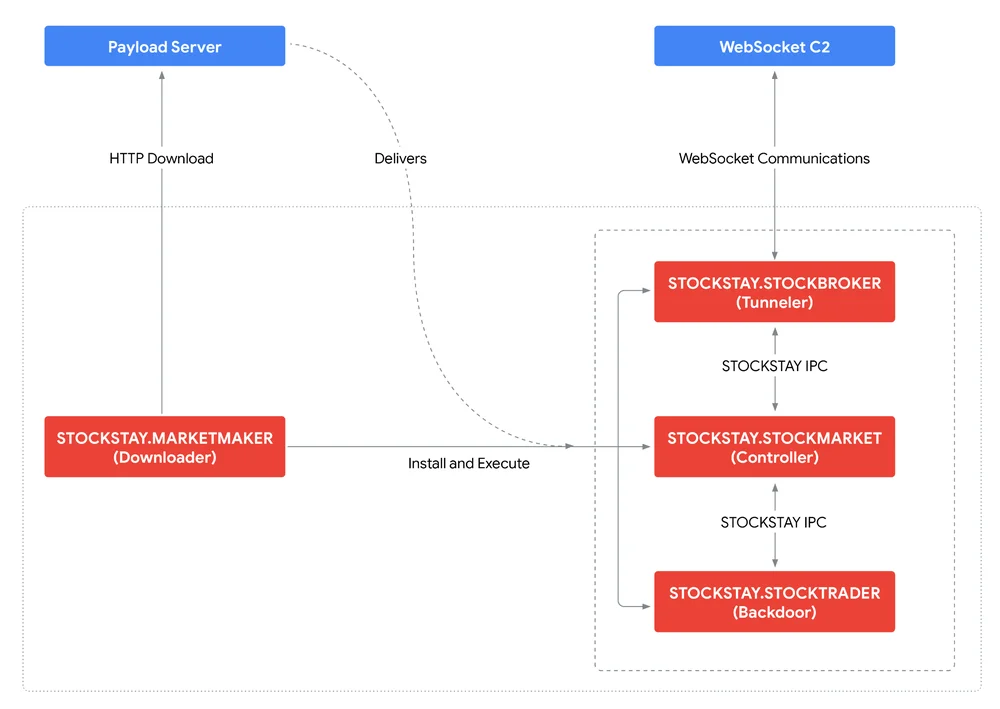
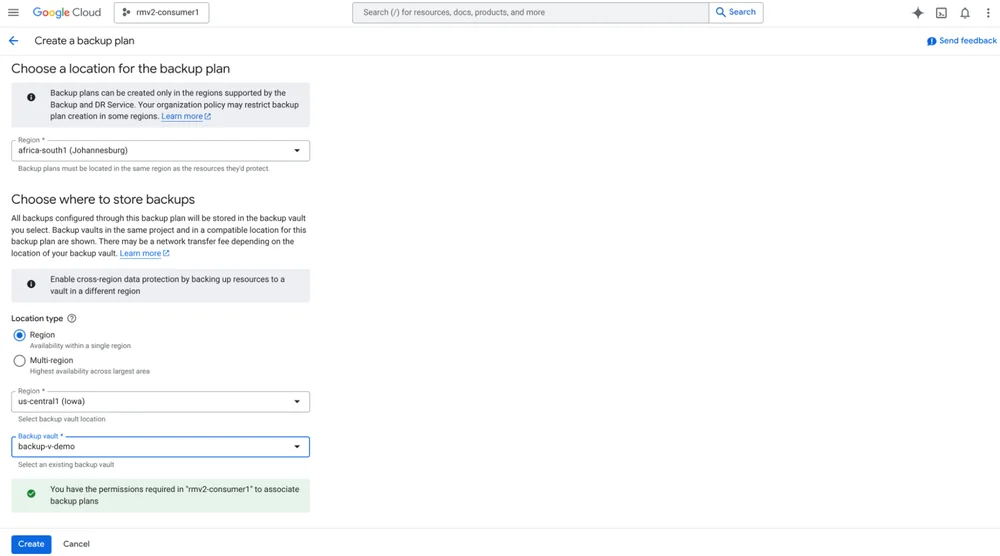
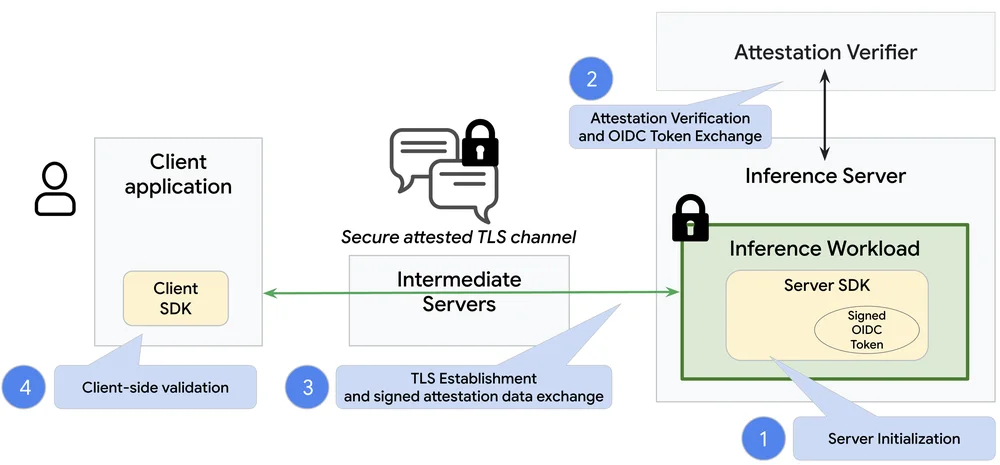
RSS 클라우드 블로그 팔로우
cloud.google.com/blog은 Google Cloud의 공식 블로그입니다. Google Cloud의 제품 및 서비스에 대한 뉴스, 업데이트 및 통찰, 클라우드 컴퓨팅 산업의 트렌드 및 혁신을 제공합니다.
이 블로그는 Google Cloud 전문가, 엔지니어 및 사상가들이 작성한 기사로 구성되어 있습니다. 인공 지능, 머신 러닝, 데이터 분석, 보안 등 다양한 주제를 다루고 있습니다. 기사들은 기술 튜토리얼, 케이스 스터디 및 베스트 프랙티스도 포함하여 Google Cloud를 사용하거나 관심이 있는 개발자, IT 전문가 및 비즈니스 리더에게 귀중한 자원이 됩니다.
블로그는 주제, 제품 및 산업별로 분류되어 있습니다. 방문객은 최신 기사를 브라우징하거나 특정 주제를 검색하거나 블로그의 RSS 피드를 구독하여 최신 뉴스 및 업데이트를 최신 상태로 유지할 수 있습니다.
블로그의 주요 기능 중 일부는 다음과 같습니다.
- Google Cloud 제품 및 서비스에 대한 심층 기사, 예를 들어 Google Cloud Platform, Google Cloud Storage 및 Google Cloud AI Platform
- Google Cloud 서비스 사용에 대한 기술 튜토리얼 및 가이드
- Google Cloud 고객의 케이스 스터디 및 성공 사례
- 산업 트렌드 및 혁신에 대한 통찰 및 분석
- Google Cloud의 파트너쉽 및 협력에 대한 뉴스 및 업데이트
- Google Cloud 전문가 및 사상가와의 인터뷰
전반적으로 Google Cloud 블로그는 클라우드 컴퓨팅, 인공 지능 및 관련 기술에 관심이 있는 모든 사람에게 귀중한 자원이 됩니다.