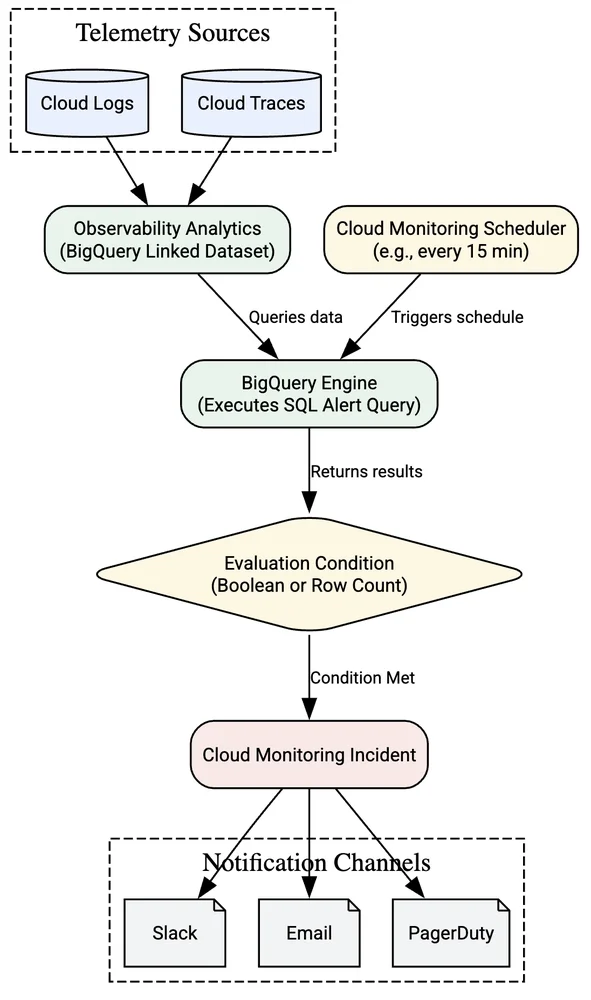
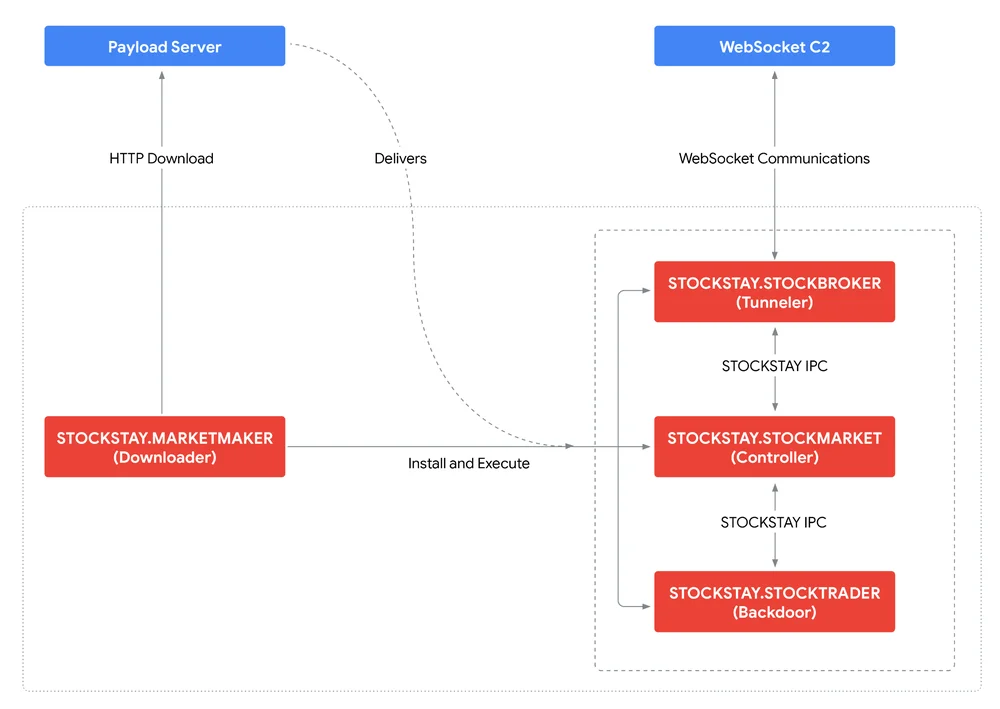
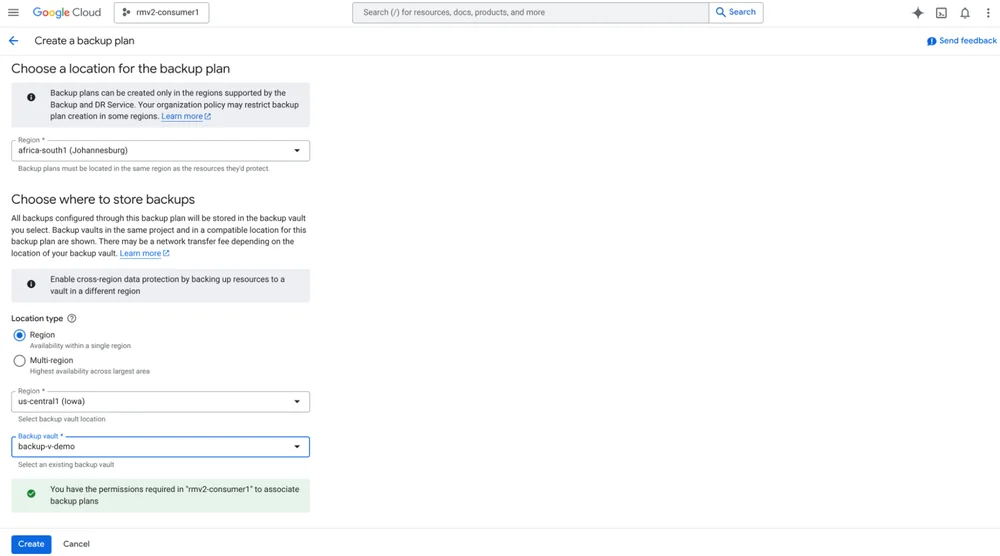
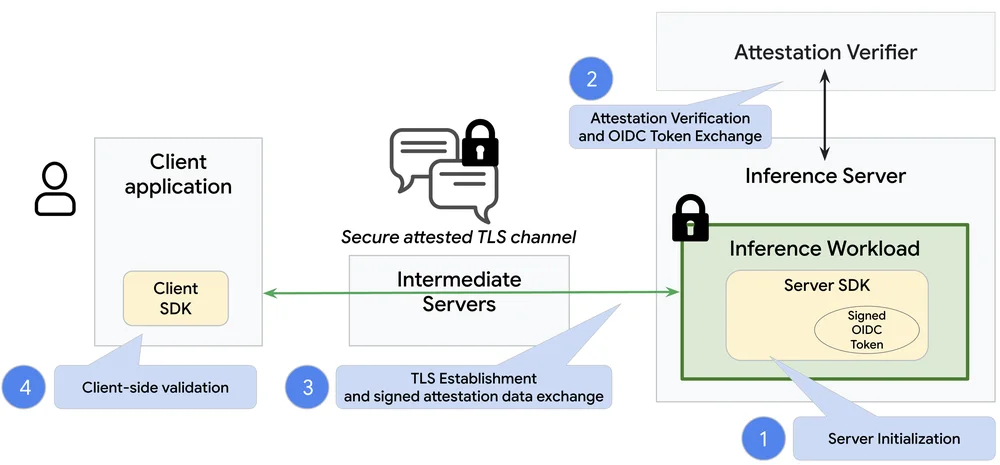
Google Cloud Blog Follow
cloud.google.com/blog is the official blog of Google Cloud. It provides news, updates, and insights on Google Cloud's products and services, as well as trends and innovations in the cloud computing industry.
The blog features articles written by Google Cloud experts, engineers, and thought leaders, covering a wide range of topics such as artificial intelligence, machine learning, data analytics, security, and more. The articles often include technical tutorials, case studies, and best practices, making the blog a valuable resource for developers, IT professionals, and business leaders who use or are interested in Google Cloud.
The blog is well-organized, with articles categorized by topic, product, and industry. Visitors can browse the latest articles, search for specific topics, or subscribe to the blog's RSS feed to stay up-to-date with the latest news and updates.
Some of the key features of the blog include:
- In-depth articles on Google Cloud products and services, such as Google Cloud Platform, Google Cloud Storage, and Google Cloud AI Platform
- Technical tutorials and guides on how to use Google Cloud services
- Case studies and success stories from Google Cloud customers
- Insights and analysis on industry trends and innovations
- News and updates on Google Cloud's partnerships and collaborations
- Interviews with Google Cloud experts and thought leaders
Overall, the Google Cloud blog is a valuable resource for anyone interested in cloud computing, artificial intelligence, and related technologies.